Tabpy連携を行うときに、Tableauの計算式にたくさん処理を書かないといけないなぁとか、毎回ライブラリのimport処理を走らせるのもなんだなぁとか、訓練データから学習したモデルを再利用したいなというときがあるかと思います。そう行った場合に、Tabpy Clientを利用できます。
Tabpy Clientを利用すると、事前に定義した関数をTabpy Server上に保存(deploy)し、クライアントからこれを呼び出し再利用することができます。
利用のステップは以下になります。
① Tabpy Serverを起動する
② jupyter notebook で事前に関数を定義し、Tabpy Serverにデプロイする
③ Tableau から計算フィールドを作成し、Tabpy Serverにデプロイされた関数にインプットを代入する
④ Tabpy Serverからの戻り値を可視化に利用する
次に具体的なステップを見ていきましょう。
まず下準備として、利用するPython環境に tabpy-client 1がインストールされている必要があります。以下のコマンドでtabpy-clientをインストールしておきます。
pip install tabpy-client
Anacondaを利用しているのであれば、Anaconda Navigator からもインストールできます。
それでは、簡単に2つの入力を足して結果を返す関数を定義して見ましょう。
① Tabpy Serverを起動する
Tabpy Serverのインストールと起動方法は以下を参照ください。
Windows:既存Anaconda環境を利用してTabpy-Serverを導入する
Mac:Mac に Anaconda 2.7 と Tabpy をインストールする
② jupyter notebook で事前に関数を定義し、Tabpy Serverにデプロイする
jupyter notebookを開きます。(作成したAnaconda環境からjupyter notebookを起動する方法はこちらを参照させていただきました。;ありがとうございます!)
tabpy_clientをinport し、接続先のTabpy Serverを指定します。
import tabpy_client
client = tabpy_client.Client(‘http://localhost:9004/’)

“add”という関数を定義します。.tolist でlist型に変換するのは、Tabpy連携でTableauから可視化する際の決まりごとなので、こういうものということでよろしくお願いします。(def 以降の行はTabでインデントします。)
def add(x,y):
import numpy as np
return np.add(x, y).tolist()
Tabpy Serverに’add’という名前でデプロイします。 override = True としておくと何度も上書きでデプロイできます。
client.deploy(‘add’, add, ‘Adds two numbers x and y’,override=True)

関数が機能するか試してみましょう。例えばこんな感じでclient.query( )でインプットを代入し結果を[‘response’]で得ます 。
x = [6.35, 6.40, 6.65, 8.60, 8.90, 9.00, 9.10]
y = [1.95, 1.95, 2.05, 3.05, 3.05, 3.10, 3.15]
results = client.query(‘add’, x, y)[‘response’]

List型で結果が返されているようです。
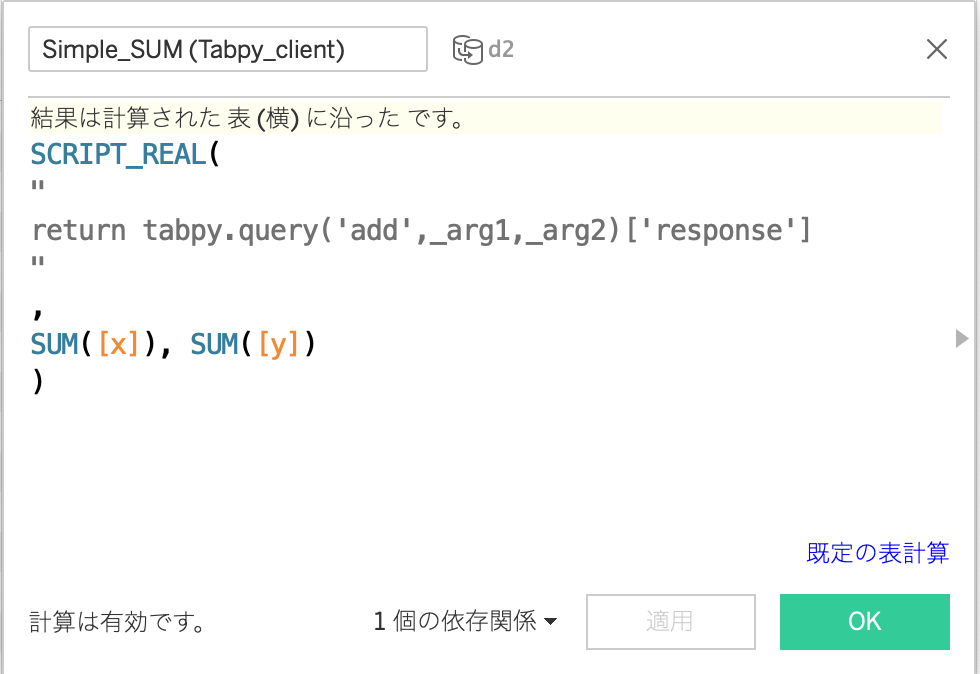
③ Tableau から計算フィールドを作成し、Tabpy Serverにデプロイされた関数にインプットを代入する
SCRIPT_REAL(
“
return tabpy.query(‘add’,_arg1,_arg2)[‘response’]
“
,
SUM([x]), SUM([y])
)
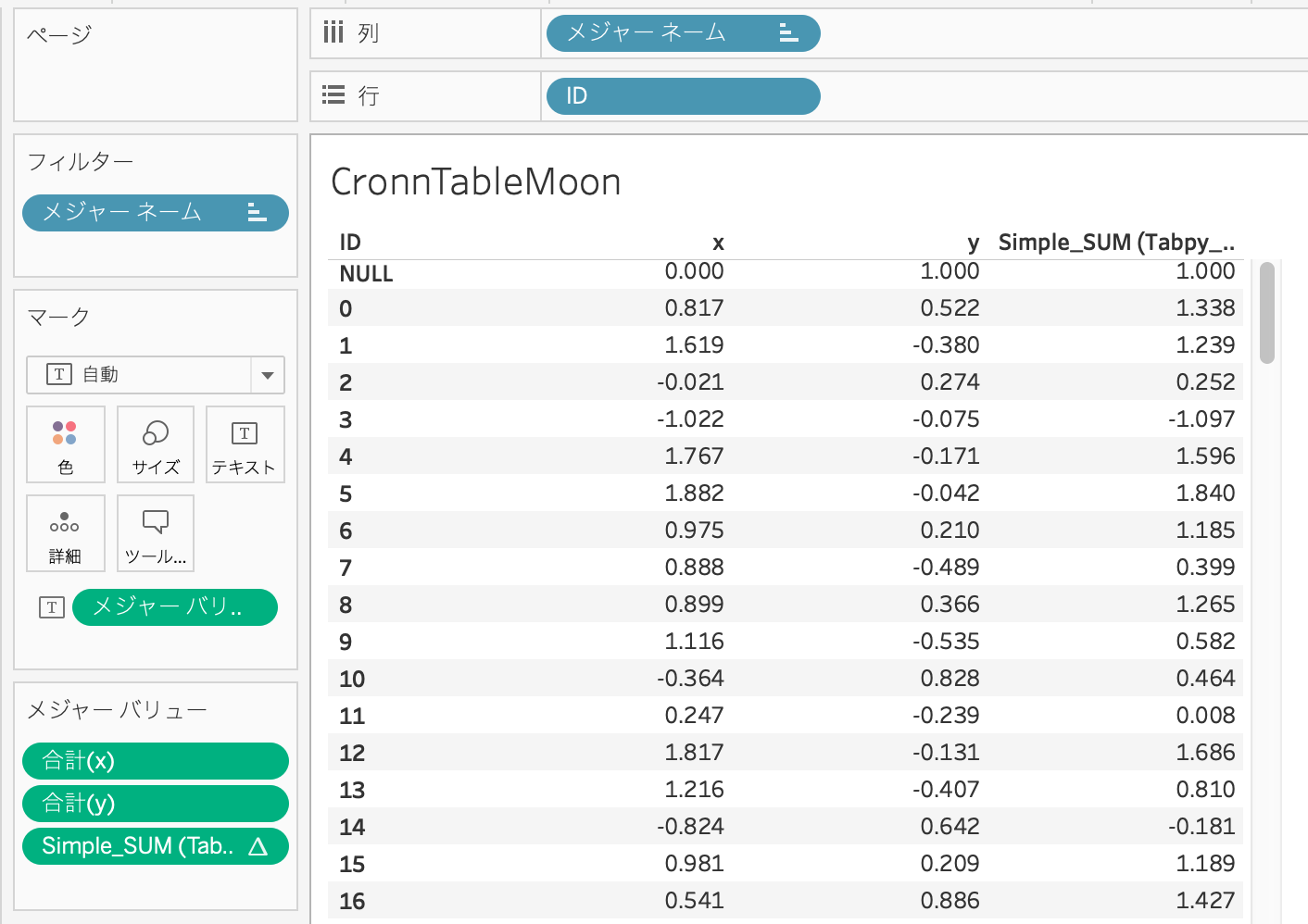
④ Tabpy Serverからの戻り値を可視化に利用する
Tableauのワークシートに結果を表示します。うまく表示できているようです。
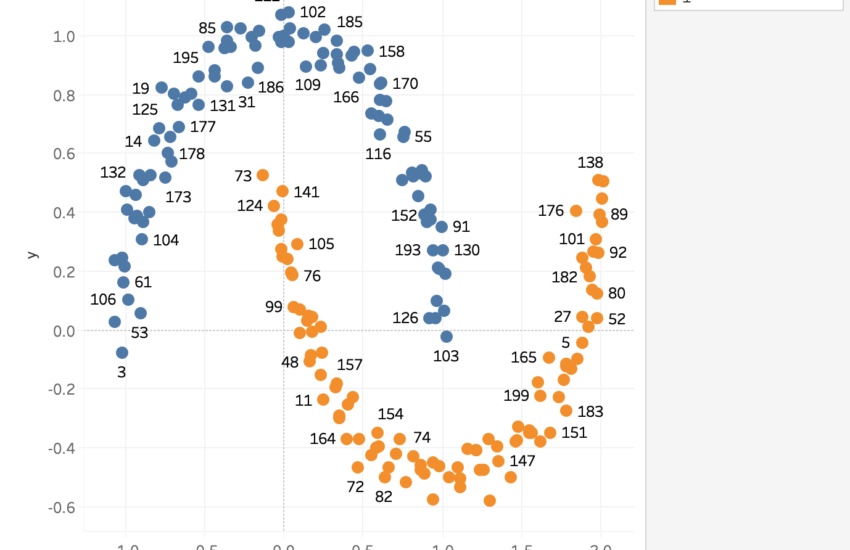
もう一つ例を取り上げてみます。
次はDBSCANによるクラスタリングの例です。
このような入り組んだ半月型をクラスタリングしてみます。(👇完成図)
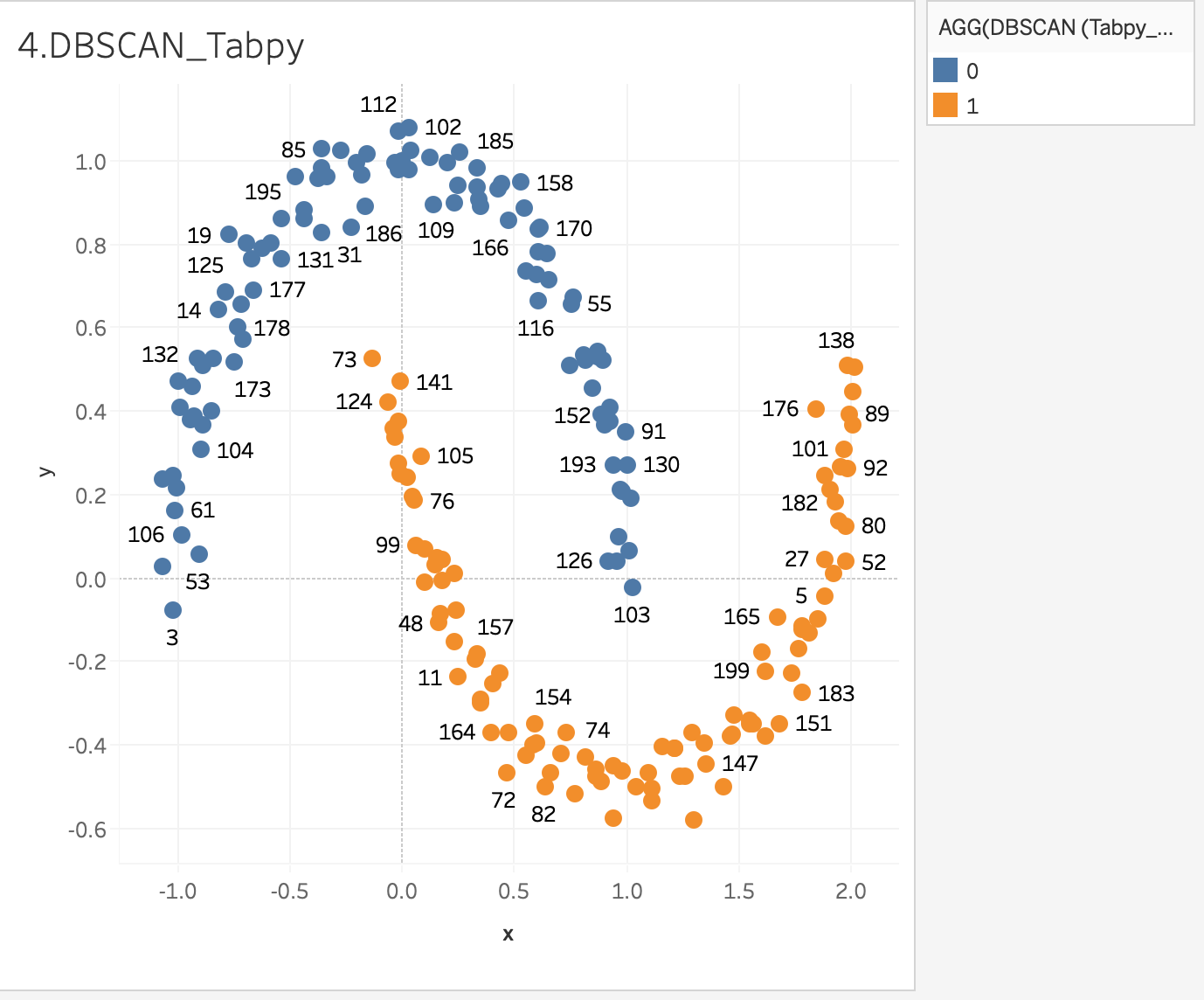
以下のようにJupyter Notebookからdbscanの関数を定義して、Tabpy clientからTabpy Serverにデプロイします。
def dbscan(x,y):
import pandas as pd
from sklearn.cluster import DBSCAN
X = pd.DataFrame(x)
Y = pd.DataFrame(y)
d = pd.concat([X,Y] , axis=1)
db = DBSCAN(eps=0.2, min_samples=5, metric="euclidean")
y_db = db.fit_predict(d)
return y_db.tolist()
client.deploy('dbscan',
dbscan,
'Returns cluster Ids for each data point specified by the pairs in x and y', override=True)

次はTableau Desktopからデプロイされた関数を呼ぶ計算式を作成します。(添付ワークブックを参照ください)呼び出すときは以下のように関数名と引数を渡すだけ。簡単です!
SCRIPT_INT(
"
return tabpy.query('dbscan',_arg1,_arg2)['response']
"
,
SUM([x]), SUM([y])
)

あとは作成した計算式をColorに入れます。(表計算の方向はCellを指定してください。)

⬇︎ クラスタリングする前

⬇︎ クラスタリングした結果を色に加えたもの
以上、Tabpy Client の利用方法でした!
参考になる記事、ありがとうございます。
書籍も参考にしながらtabpy clientをインストールしてみたのですが
jupyter notebookで「import tabpy_client」を実行すると
‘ invalid character in identifier’のエラーが出てきてしまいます。
コマンド プロンプト では確かに仮想環境上でtabpy clientがインストールできているようなのですが・・・
何か考えられる原因はありますでしょうか?
すみません、エラーですが
‘No module named ‘tabpy_client’でした。
つまりtabpy clientがインストールできていないということみたいです。
ただターミナルでは問題なくできているようなのですが・・・
何度もすみません。
モジュールを探索するパスが通っていなかったようで、パスを通したらエラーが出なくなり、無事にインポートできました!
以下のサイトを参考にしました。
https://qiita.com/arumiti/items/835e87c35dcbb69d8ca2
Shibata San ありがとうございます!きっとこの情報が皆様の役に立つと思います。これからもよろしくお願いします!
import tabpy_client
client = tabpy_client.Client(‘http://localhost:9004/’)
私も全く同じエラーにはまっています。
No module named ‘tabpy_client
https://qiita.com/arumiti/items/835e87c35dcbb69d8ca2
上記のShibataさんの残してくださったQuiitaの記事を参考にしていますが、「パスを通す」ということができませんでした。
①捜索場所を確認する
import sys
print(sys.path)
→これは問題なく実行でき確認できました。
②保存先を確認する
pip show
→
pip show tabpy_clientで実行しました
[Note: you may need to restart the kernel to use updated packages.]というメッセージがでます
=アップデートされたパッケージ(ここでは seaborn )を使うには kernel を再起動する必要がある
添付画像のように上部タブの[kernel]クリック、[Restart]クリックしてから、再実行しても変化なしです
もしおわかりになりましたら、どうぞよろしくお願い致します。
一晩たって、再度同じことをやったら(特に修正していないです)
import tabpy_client
client = tabpy_client.Client(‘http://localhost:9004/’)
できました。