※ 本記事は先進的な技術情報を共有するための目的で作成しており、Tableau 社およびGroovenauts社からの正式リリース発表とは一切関与がございません。以下情報に関するTableau 社のサポート問い合わせの対象にはなりません。ご理解の上参照頂ければ幸いです。
皆様、毎日暑いですね!皆さまいかがお過ごしでしょうか?・・・ということで、今回はGUIでニューラルネットワークベースの予測モデルを作成できるGroovenauts(グルーヴノーツ)社のMAGELLAN BLOCKS(マゼランブロックス)とTableau を連携して、真夏の東京電力の電力需要を予測してみたいと思います。
◆ MAGELLAN BLOCKSとは?

福岡発AIベンチャーの株式会社グルーヴノーツが開発・提供する「MAGELLAN BLOCKS」は機械学習・深層学習をベースとした予測モデルの作成を、ブロックを繋ぐというGUI操作で実現できるクラウドAIサービスです。以前こちらの記事で紹介させていただきましたが、Pythonでニューラルネットワーク予測モデルを作るには、それなりにコーディングの知識が必要となりますし、ハイパーパラメータのチューニングも色々色々試してみないと精度が出ません。そういった苦労の数々をまるっと実施ししてくれるのがMAGELLAN BLOCKSです。量子コンピュータ・AIを活用した「MAGELLAN BLOCKS」サービス概要についてはこちらをご参照ください。
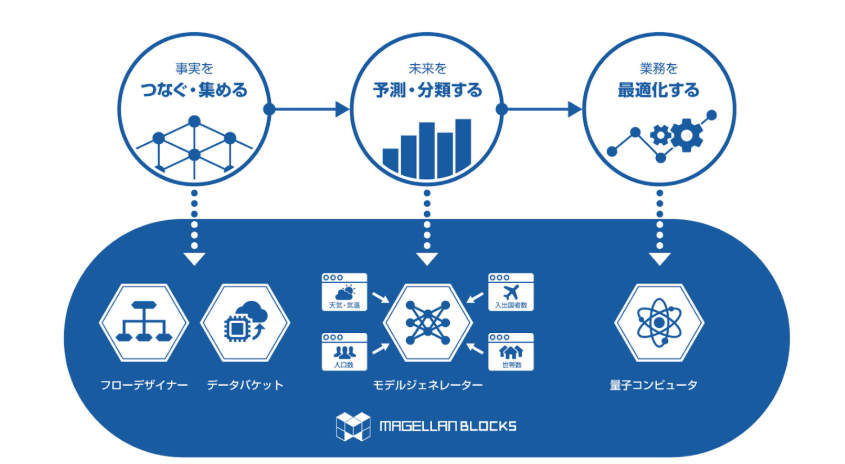
今回はTableau Prep Builder でデータ準備し⇒MAGELLAN BLOCKSで予測⇒Tableau Desktopを使って結果の可視化・・・と連携することで、データサイエンスのプロセスをぐるっと回すことができるという事例を紹介したいと思います。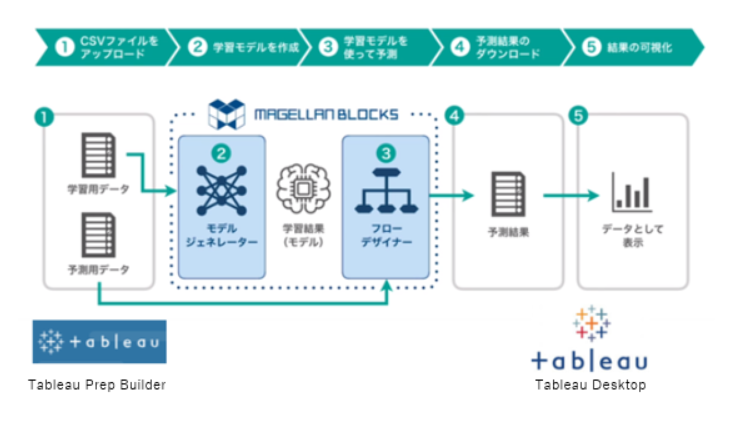
それでは早速実際のデータを使ってTableau とMAGELLAN BLOCKSの連携を体験していきましょう。必要なステップは以下のようになります。
ステップ:
① Tableau Prep Builderによりデータ準備作業をフロー化する
② Tableau Desktopの可視化により必要な特徴量(説明変数)を考える
③ MAGELLAN BLOCKS(モデルジェネレーター)を使って気象情報から電力の需要予測モデルを作る
④ MAGELLAN BLOCKS(フローデザイナー)を使って予測値を得る
⑤ Tableau Desktopで誤差を評価する
⑥ 調整済みのモデルを利用して2019年の電力需要予測を行う
詳細:
次にそれぞれのステップの詳細に入っていきます。
① Tableau Prep Builder によりデータ準備作業をフロー化する
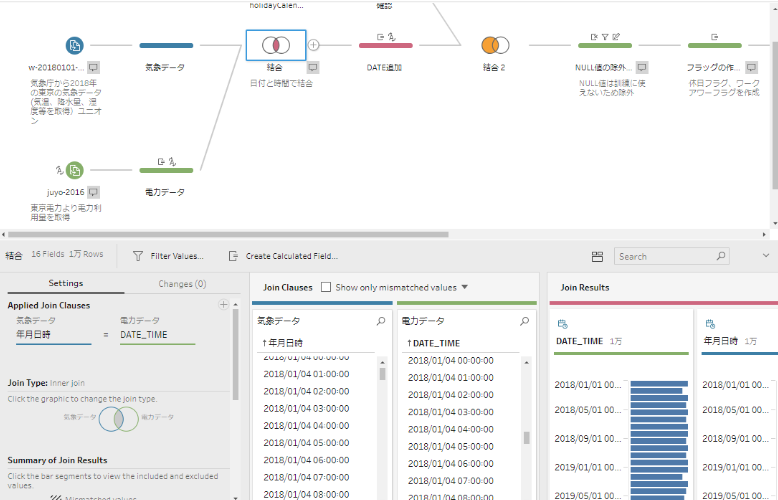
気象庁より2018年の気象データ、東京電力より2018年の供給電力データをダウンロードします。それぞれのデータは年月日と時刻(1時間)ごとでデータが存在するので、この日付+時刻をキーとして2つのデータを結合します。Tableau Prep Builderを利用すれば簡単に結合できますし、結合後の不要列の削除、NULL値の削除、曜日フラグの作成等も、一度フロー化してしまえば後から何度でも実行することができます。
② Tableau Desktopの可視化により必要な特徴量(説明変数)を考える
Tableau Desktopを使ってデータを理解していきましょう! さて皆さん、電力利用量に関与する気象情報ってなにがあるんでしょうね? 天気? 湿度?・・・ まぁ、私の家でも夏はクーラーを使わざるを得ないのでやはり電気量が上がるのですが、気温に関係があるのでは?とまず思いつくところです。本当にそうでしょうか?可視化してデータを理解してみましょう。
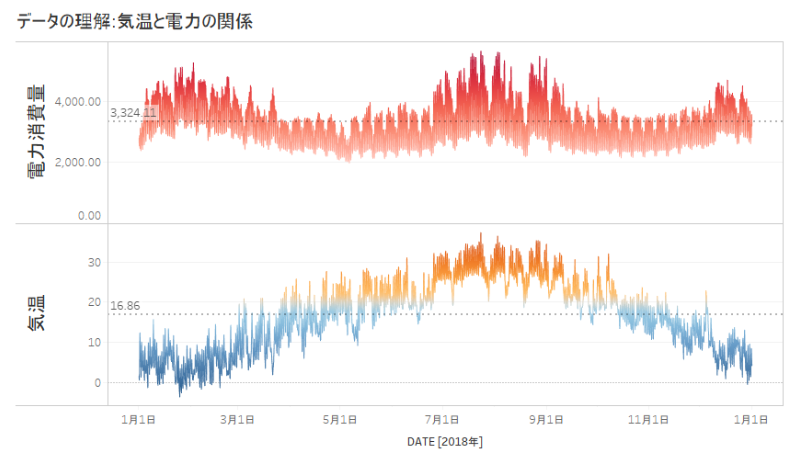
Tableau で日付を横軸(列)に、電力と気温を縦軸(行)にドラックすると簡単に傾向をみることができます。下図の上段が電力消費量、下段が気温です。平均気温から離れる(暑い、寒い)時に電力使用量が増えることが分かりますね。つまり、気温は説明変数として電力予測に利用できそうです。
曜日と時間帯でも傾向があるか見てみましょう・・・Tableau でヒートマップを書いてい見ると 時間帯、曜日(平日・土日)によって電力利用量に差があることが分かります。ここから、曜日、時間帯を説明変数として採用すると良さそうです。
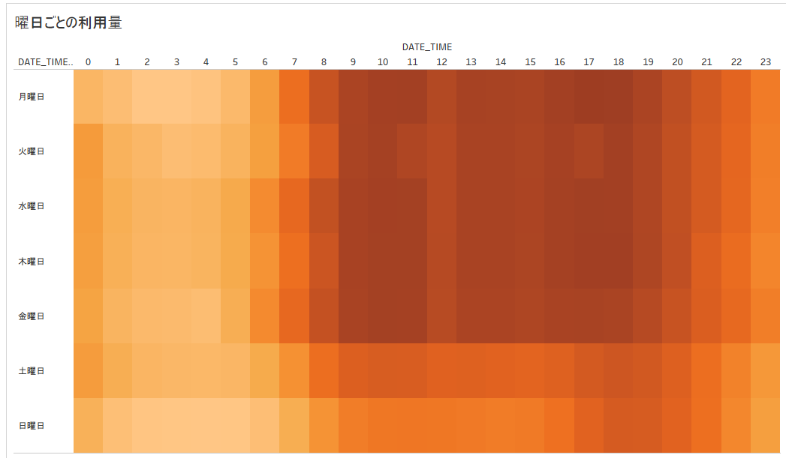
また、以前の記事 での気づきでもあったのですが、予測モデルを作るときに、正月、ゴールデンウィーク等の祝日は電力消費量が少ないことが分かりましたので、祝日カレンダーを作り、データと外部結合して祝日フラッグを作成、これを説明変数として入れ込むことにします。
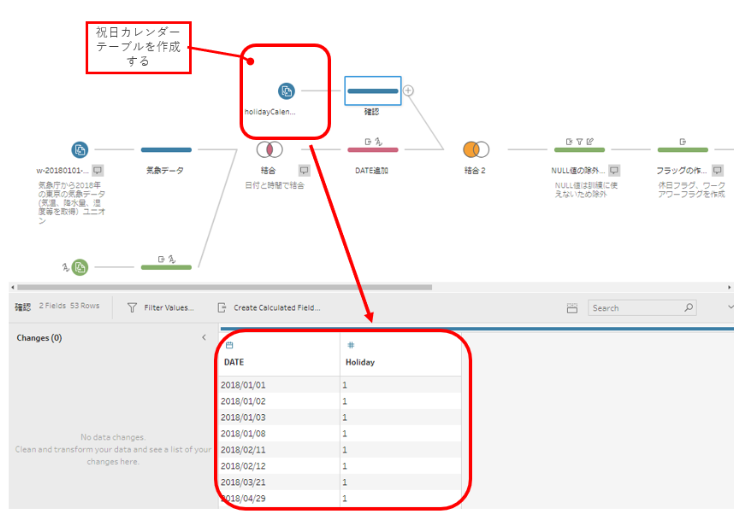
最終的には以下のような訓練データをTableau Prep Builderを使って生成しました。

MAGELLAN BLOCKSを使って気象情報から電力の需要予測モデルを作る
MAGELLAN BLOCKSで予測値を得るためのステップはザックリ分けて以下のようになります。
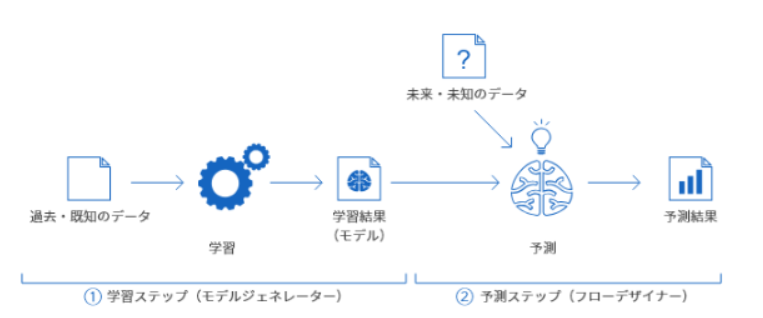
1. 学習ステップで過去のデータから学習を行います。このステップではMAGELLAN BLOCKSのモデルジェネレーターというツールを利用します。
2.予測ステップで学習結果を使って予測(分類や回帰)を行います。このステップではMAGELLAN BLOCKSのフローデザイナーというツールを利用します。
③ 予測モデルを作成する(モデルジェネレーター)
まず、ブラウザーで、MAGELLAN BLOCKS にログインし、メニューからモデルジェネレーターを開きます。こちらがモデルジェネレーターの初期画面です。「利用を開始」ボタンをクリックします。
ここから学習データを用いた予測モデルの作成を行います。ここでは数値回帰モデル(電力利用量を数値として予測する)を選びます。

予測サービスの名前を設定します。
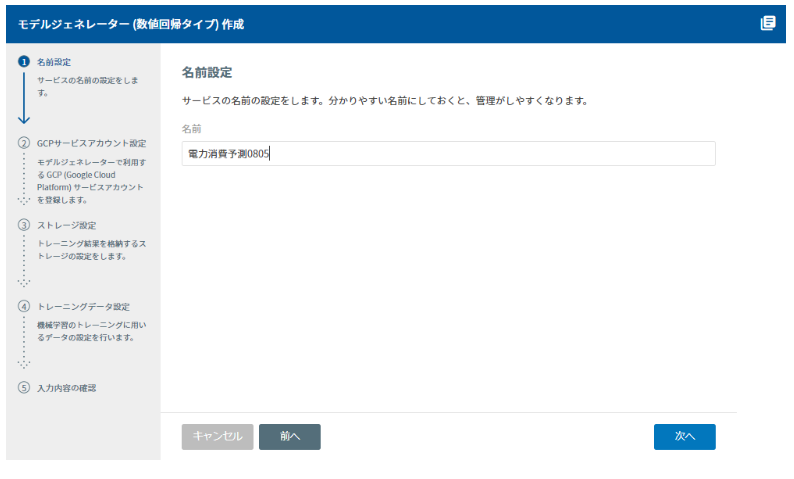
MAGELLAN BLOCKS利用の際にはGCP(Google Cloud Platform)アカウントが必要となります。必要なAPIが利用可能になっていることを確認します。
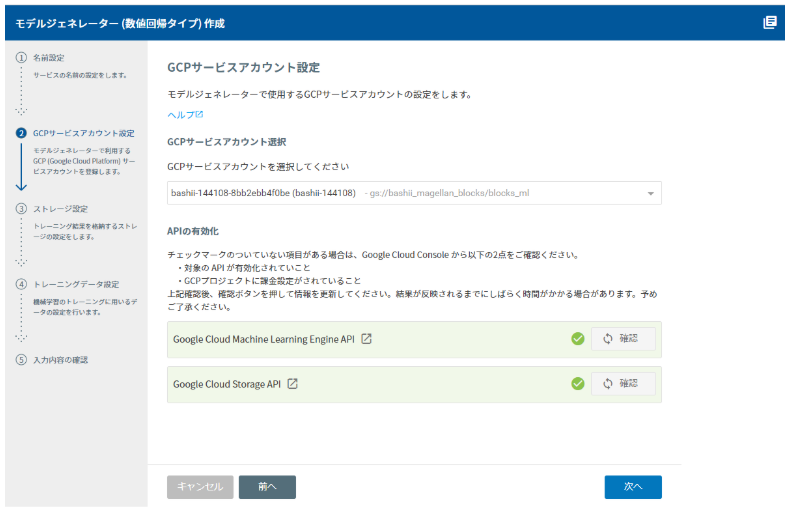
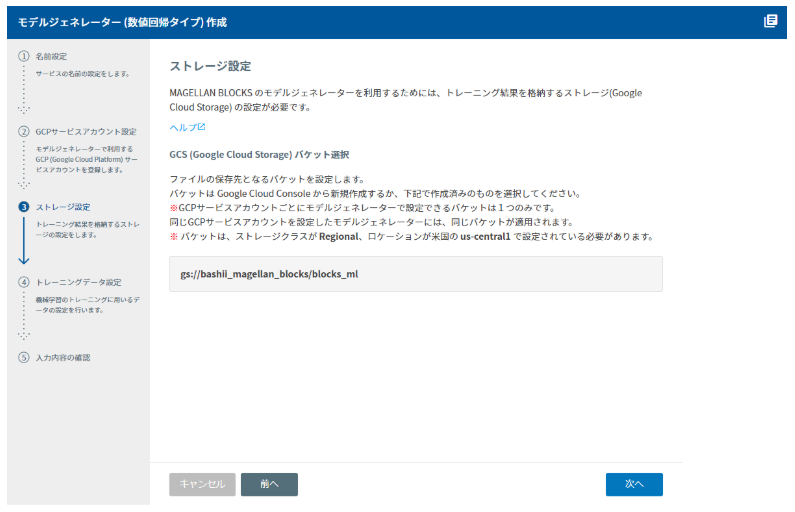
トレーニングの結果を格納するGoogle Cloud Storageのバケットを指定します。あらかじめ訓練データはGoogle Cloud Storage にアップロードしておきます(MAGELLAN BLOCKSのメニューからGCSマネージャーを使って簡単にアップロードすることができます。)
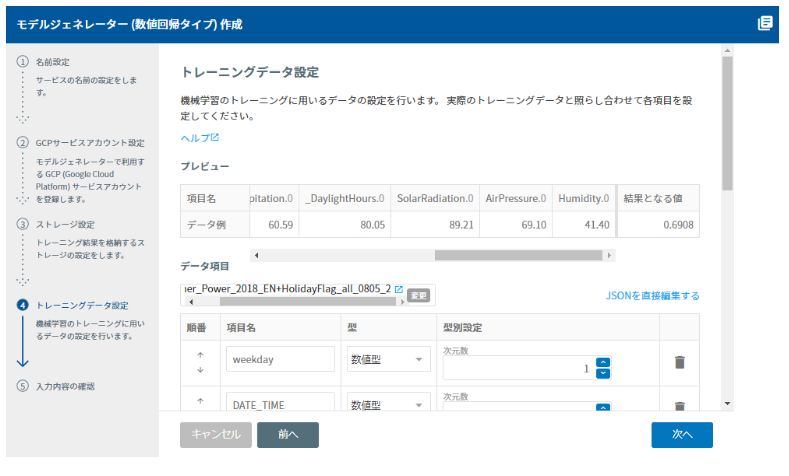
次に、訓練データから説明変数の設定を行います。訓練データの一番右端のデータが目的変数として利用されます(この場合は kw )。説明変数のデータ型(数値型なのか、文字列型なのか、フラグ型なのか等)を指定します。
モデル作成が完了するまで待ちます(今回の場合はだいたい4時間くらいかかりますので、一旦パソコンは閉じてひと休みしましょう・・・)。
モデルの作成が完了するとステータスが緑色の「成功」になるので、モデルを本番用として適用します。ここで、誤差を確認しますここでは 246.750 となりました。誤差の意味と確認方法についてはこちらを参照ください。
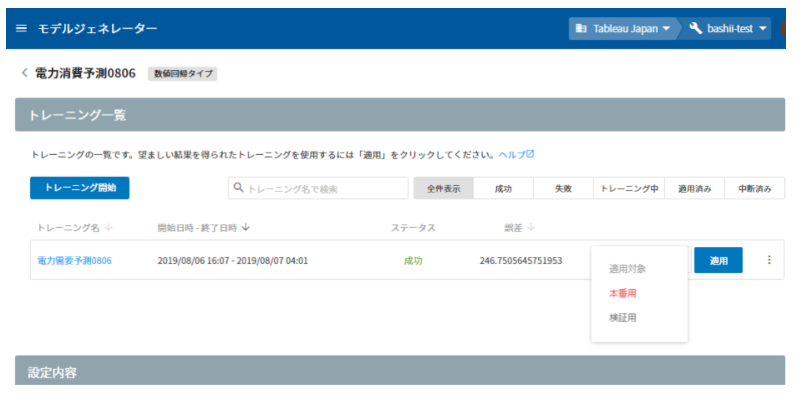
④ MAGELLAN BLOCKS(フローデザイナー)で予測値を得る
前のステップで作成したモデルを使って、実際に予測値を取得しましょう。
MAGELLAN BLOCKSではフローデザイナーというツールを使って、予測値を得るための処理をフローとして定義します。ここで予測モデルに投入するテストデータ、実行形式、出力データ等の設定を一連の処理ブロックとして定義し、このブロックを繫げてフローを作成、実行する仕組みになっています。
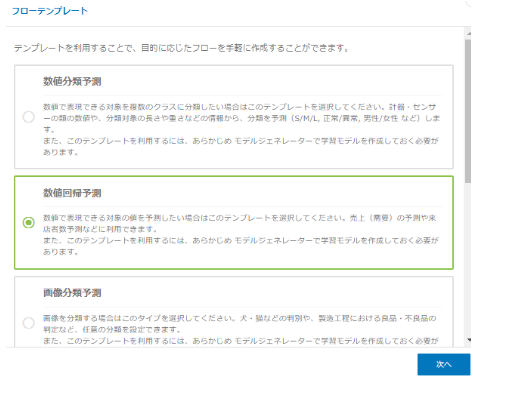
良く利用される予測フローはテンプレートが既に準備されています。モデルジェネレーターのタイプ(数値回帰予測)のテンプレートを利用します。
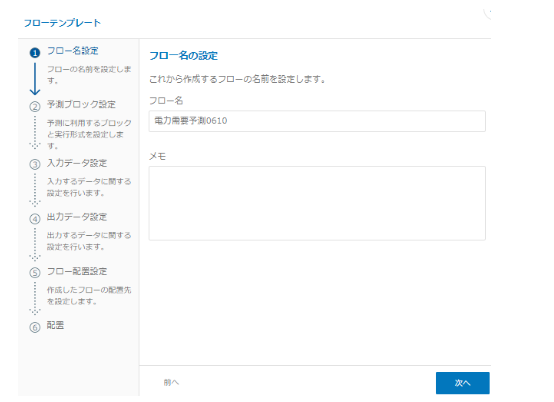
フローの名前を付けます。
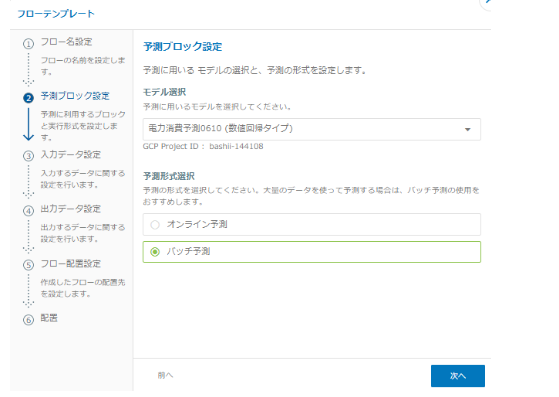
利用するモデル(前のステップで作成したもの)を指定します。
入力データとしてモデルに投入するテストデータを定義します。(ここではGCS上にアップロードされたCSVファイルを指定します。)まずはモデル作成で利用した訓練データである2018年のデータをテストデータとして予測値を取得し、どのように誤差が出ているか分析してみましょう。
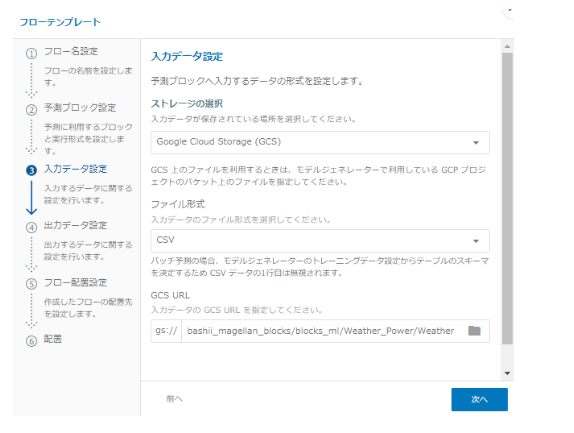
予測結果の保存先を指定します。(ここではGCS上のCSVファイルとします。)
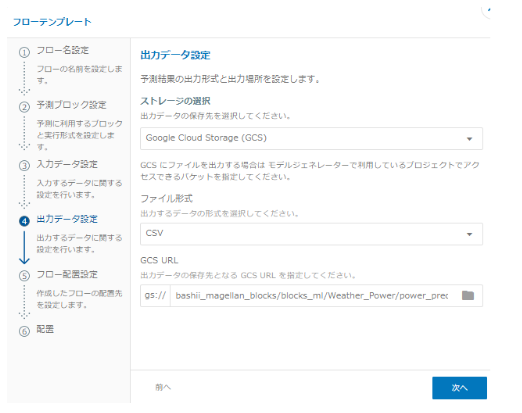
フローの配置を完了します。
フローの作成と配置が完了したらフローを実行します。フローの実行が完了するまでしばらく待ちます。
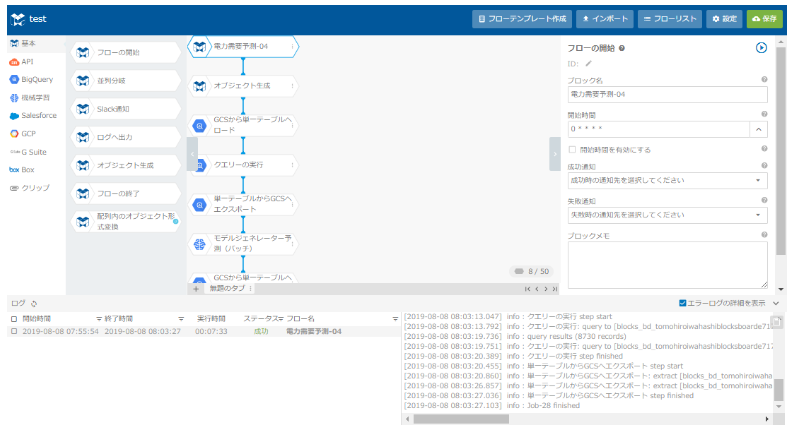
GCSエクスプローラ(GSC上のファイルを管理するツール)で指定した場所に予測結果のファイルができていることを確認し、これをダウンロードします。
ダウンロードしたファイルには以下のように、key と予測値(output)が含まれています。
ここまでで、MAGELLAN BLOCKSによる予測値の取得は完了です。次にTableau を使って予測値を可視化して評価してみましょう。
⑤ Tableau で誤差を評価する。
訓練データとMAGELLAN BLOCKSによって生成された予測値は別ファイルとなっていますので、これを日付時刻をキーとしてジョインし、実際の電力消費量と予測値を比較できるようにします。
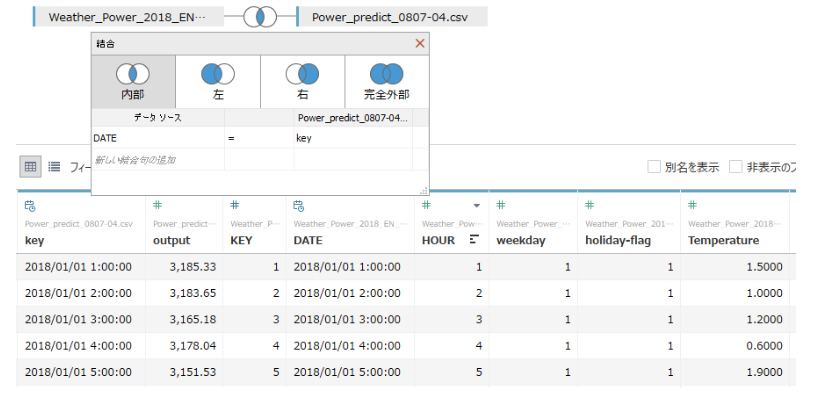
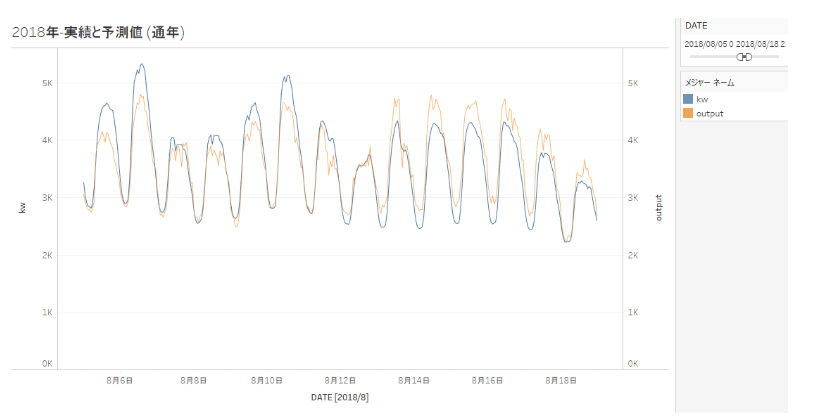
2018年のモデルについて実測値と予測値を比較・可視化します。横軸に日付時刻、縦軸に実際の電力消費量(青色)とMAGELLAN BLOCKSが出力した予測値(オレンジ色)を重ねて表示します。ほぼ波形が一致しているので、おおよそ当てはまりの良いモデルが出来ているということが目で見て理解できます。
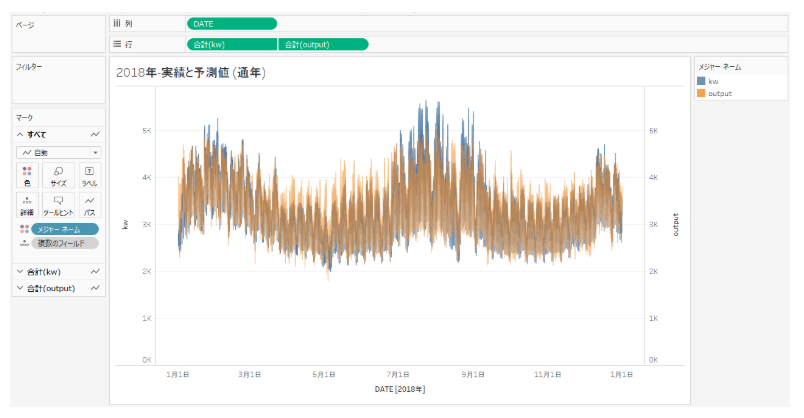
日付にフィルタをかけることで、去年の夏、8月初旬に特定して実績と予測の比較をしてみます。2018年の8月6日~8月10日にかけては実績(青色)が予測(オレンジ色)より大きい一方で、お盆に入った8月14日の週は実績(青色)が予測(オレンジ色)を下回っているので思ったより電力利用が少なかったようです。
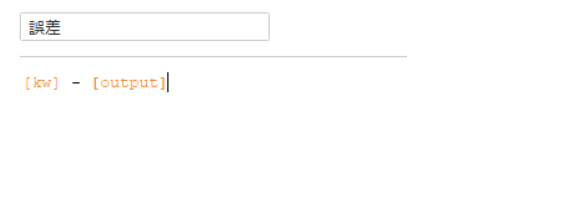
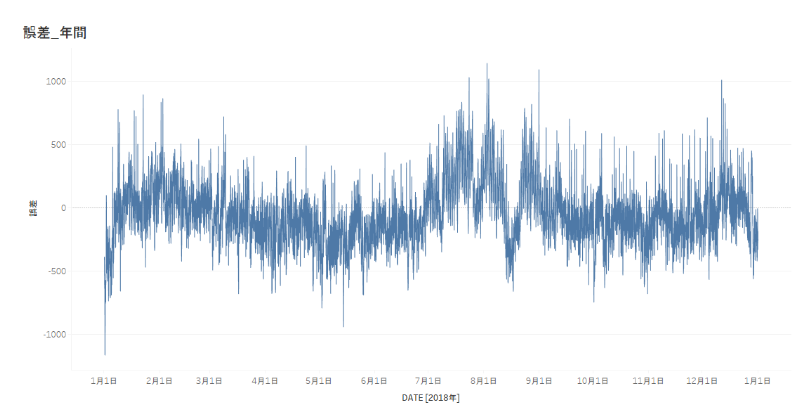
また、誤差を以下のように計算式を作成して新しいメジャーとして作成し、時系列に可視化してみます。
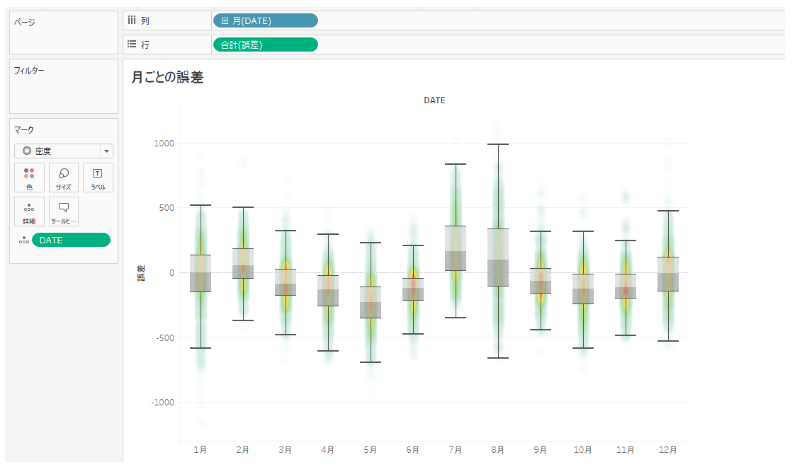
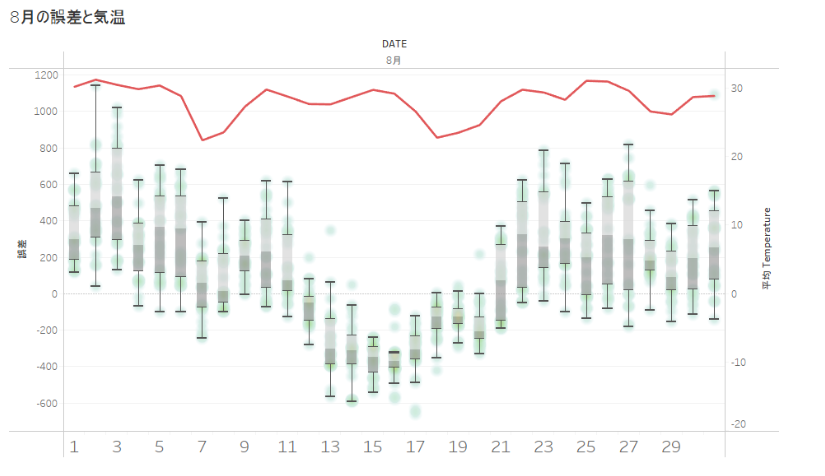
誤差の分布を月ごとに箱ひげ図で見てみると、8月の誤差はプラス、マイナスで開きが大きいですね。
8月についてもう少し誤差の開きの理由を探ってみましょう。2018年の8月の誤差(実績ー予測)分布と気温の関係を可視化してみます。真ん中がへこんでいるのはお盆で実績が少ないのでしょう。また平均気温が高い日(赤色線)は誤差がプラス方向にふれているので、実績が高い(予測より多く電力を使っている)といった傾向があるようにも見えます。
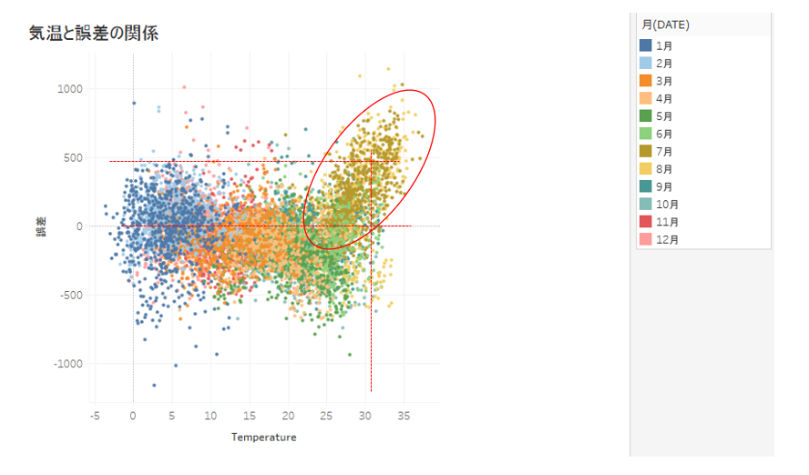
もう一つ、気温(X軸)と誤差(Y軸)を散布図で表現してみます。すると右上に角のような分布が見られます。気温がおよそ30度あたりを超えると誤差がプラスに振れるようにも見れます。(あくまで主観ですが・・・いかがでしょうか?) ここから、仮説として、30度を超えると電力実績が予測を上回る。つまり「猛暑日フラグ」を作って更にこれを説明変数として入れてもう一度予測モデルを作るというのありかもしれません。
今回はこれ以上の説明変数の調整とモデルの再作成は行いませんが、より高い精度のモデルを作成するために 特徴量の生成⇒ モデルの作成⇒ モデルの評価と行ったプロセスのサイクルを回していくことになります。
⑥ 作成済みのモデルを利用して2019年の電力需要予測を行う
それでは最後に、2018年の訓練データを利用して作った2018年の予測モデルを使って、2019年7月から8月12日まで電力需要予測を行います。
予測モデルに投入する入力データ(説明変数)を以下のように作成します。2018年の訓練データと違うところとしては、ユニークなIDとして使用するDATE_TIME列を含め、これを”key”という名前に変更しておくことと、予測対象であるkw がないことです。

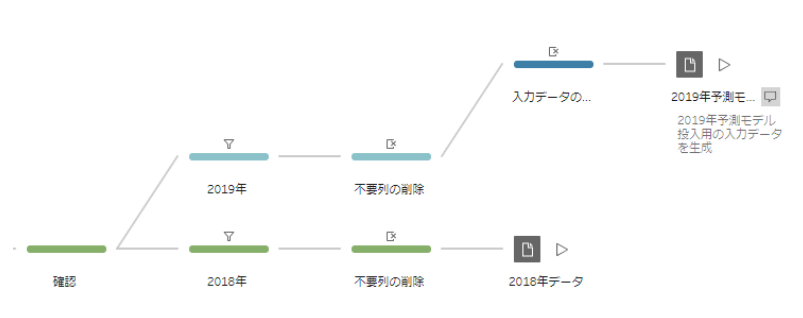
このようなデータもTableau Prep Builderで検証用(2019年)の分岐を作成することで簡単に実行できます。
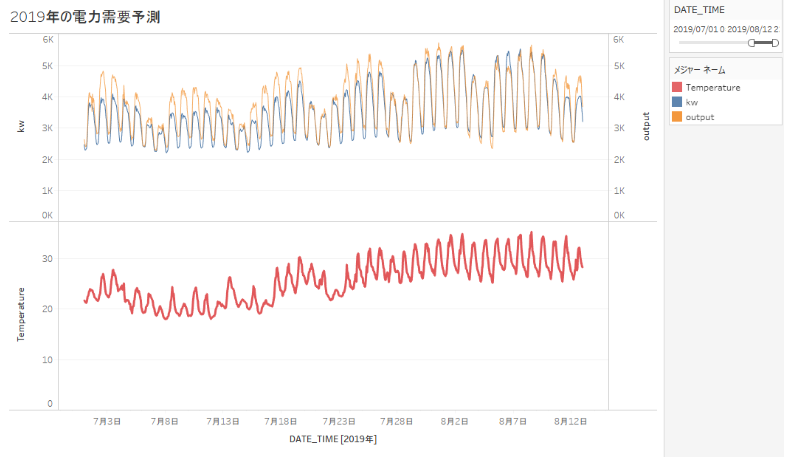
「④ MAGELLAN BLOCKS(フローデザイナー)で予測値を得る」で実施した手順と同様に、2018年の訓練データを利用したモデルを利用して、2019年7月から8月現在についての電力需要予測値を取得します。以下が2018年のモデルを利用して予測した2019年(7月1日から8月12日まで)の電力予測を可視化したものです。青が2019年の電力使用実績、オレンジがMAGELLAN BLOCKSによる電力需要予測、赤が気温です。2018年のモデルを使って、2019年についてもそこそこ良い予測ができているようです。今年(2019年)は7月の終わりまで梅雨が続いて気温が低かったので、7月は予想より実績が低いのかもしれませんね。
ということで結論です:
結論:
Tableau とMAGELLAN BLOCKSを連携することにより、ドメイン知識に基づいた特徴量の抽出し、ニューラルネットワークの予測モデルを高めることができることが分かりました。また結果を可視化で評価することで、誤差の出ている箇所を追求し新しい特徴量作成に繫げることができました。
TableauとMAGELLAN BLOCKSを連携することでコーディングをすることなく、ドラック・アンド・ドロップでデータサイエンスのプロセスが回せます。皆さんも是非お試しください。(MAGELLAN BLOCKSのトライアルはここからできます。2019年8月現在)
今回はMAGELLAN BLOCKSによる数値の予測(回帰予測)を行いましたが、その他にも以下、のような用途が考えられるということです。画像認識、自然言語、気象データの応用や量子コンピュータによる最適化等、ノンコーディングで最先端の分析テクノロジ―を利用できるのですね・・・試してみたいです!
(例)
・数値分類による成約率予測:単純な顧客リスト抽出でテレマーケティングをしているため成約率が悪いという課題に対し、成約率の高い顧客から効率的にコールできるため、成約数が向上し売上増加を実現可能に。
・気象庁データ(天候)や近隣の人流データ等も用いて数値回帰による来店客数予測から量子コンピュータを活用した最適なシフト作成:人手をかけて作成していた複雑な勤務シフトも、最適な人員配置を実現することで、余剰人員コストの圧縮が可能に。
(MAGELLAN BLOCKSの「Data Editor」では、全国155ヶ所の気温・湿度・日照時間等の気象データセットを提供。AIの予測因子としてそのまま活用可能)
・文書検索 / 自然言語分類にて意味的近さを捉え類似性の高いものを高速検索。FAQシステムに組み込むことで、問い合わせ対応負荷を削減可能に。
・画像分類による不良品判定:工場での目視検査に多くの工数が必要となっており、また人材不足により生産数量の制約が発生している課題に対し、不良品の検品作業負荷を下げ、他の重要な作業への時間割り当てや、生産数量の増加を実現可能に。
・数値回帰による需要予測から量子コンピュータを活用した配送ルートの最適化:無駄な移動コストの圧縮と同時に輸送量の増加が可能に。
以上、Tableau とMAGELLAN BLOCKSを連携し、気象データと電力需要データを用いてデータサイエンスのプロセスを回してみる事例をご紹介しました。参考いただければ幸いです。
※ 本記事の作成にあたり、Groovenauts社 二角 直秀 さん、金田 裕美 さんにサポート頂きました。こころから感謝いたします。