※ 本記事は先進的な技術情報を共有するための目的で作成しており、Tableau 社から正式リリース発表とは一切関与がございません。リリース前のバージョンに関する、動作、仕様はリリース時に変更となる場合がございます。以下情報に関するTableau 社のサポート問い合わせの対象にはなりません。ご理解の上参照頂ければ幸いです。
Tableau 2019.3 の新しい機能として、Tableau Prep からPython・Rコードを実行できる機能が追加になる予定です。(現時点で予定であり、予告なく変更される可能性がございます。)
今回は現在ベータ版2019.3が公開されているTableau Prep Builder 2019.3 の新機能であるPython連携についてその可能性を探っていきたいと思います。Tableau Prep Builder 2019.3ではR連携とPython連携が可能になりますが、この記事ではPython連携について紹介します。
こちらの内容はベータ版2019.3に登録、ダウンロードし、PythonスクリプトファイルとTableau Prep Builderのフローファイルをこちらからダウンロードする事でお試しいただけるはずです。
目次
0. Tableau Prep + Python 連携の何が嬉しいのか
1.「データセットを読み込んでそのまま出す」
2. 行番号を振る
3. ソートしてトップ10を返す
4. K-meansクラスタリングを実施する
5. データベースへの書き出し (2019-07-14 追加)
99. デバッグの方法
——————————————
0. Tableau Prep + Python 連携の何が嬉しいのか
そりゃもう、嬉しいです!! Python でできるデータフレームの処理がほとんどできてしまうのですから、コーディング次第でなんでも出来てしまうということです。例えばデータの前準備処理では、行番号を振ったり、ソートして上位の特定行を取ったり、重複行を排除したり、一行前と比較したり、ランダムに抽出したり、データベースに書き込んだり・・・と色々考えられます。また、機械学習のプラットフォームとしてPython上で利用できる多用な予測モデルを使って予測値を得るということもできます。本当に使い道次第で可能性が広がりますね!
Tableau Prep BuilderとPython を連携するステップは以下のようになります。
a.Tabpy Serverをセットアップ、起動する
b.Pythonスクリプトを準備する
c.Tableau Prep BuilderからPython関数を実行するステップを追加する
1.「データセットを読み込んでそのまま出す」
まずは本当に簡単な「データセットを読み込んでそのまま出す」という処理をしてみましょう
1-a.Tabpy Serverをセットアップする
Tabpy Serverのセットアップは以下のリンクを参照ください。
既存Anaconda環境を利用してTabpy-Serverを導入する
Mac に Anacondaと Tabpy をインストールする
Tabpy Serverを起動するとデフォルトでポート9004でリッスンします。

1-b. Pythonスクリプトを準備する
以下 ParseData.py というファイルを作成します。(こちらからダウンロード)

中身は以下です。 ParseDataという関数が定義されており、Pandasのデータフレーム”df”を引数にしていて、そのまま ”df”を返すというだけのシンプルな内容です。Pythonではタブのインデントにより関数の中身を記述するので、インデントに注意ください。コピペするとインデントが消えることがあります。
# ParseData.py の内容
def ParseData(df):
# Here you can implement logic to transform data .
return df
1-c. Tableau Prep BuilderからPython関数を実行するステップを追加する
まずはおなじみIRIS(あやめの花の属性)のデータに接続します。(こちらからダウンロード)
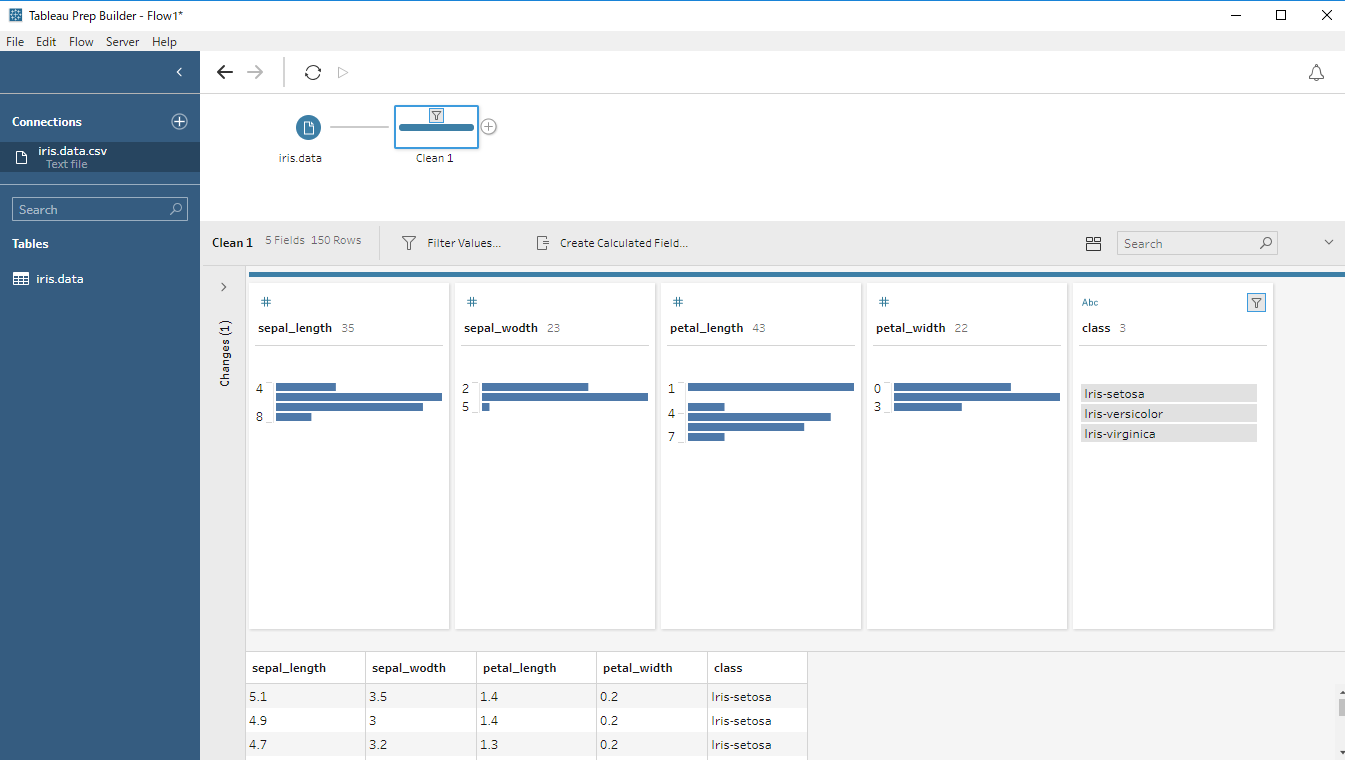
ここでステップを右クリックすると「Add Script」が選択できるようになっています。これです。
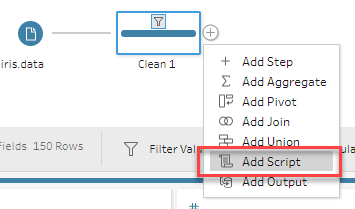
「Connection Type」でTableau Python (Tabpy) Server を選択し、「Connect to Tableau Python (Tabpy) Server」を選択、ServerとPortを設定します。今回はlocalhost/9004です。Sign In ボタンを押します。
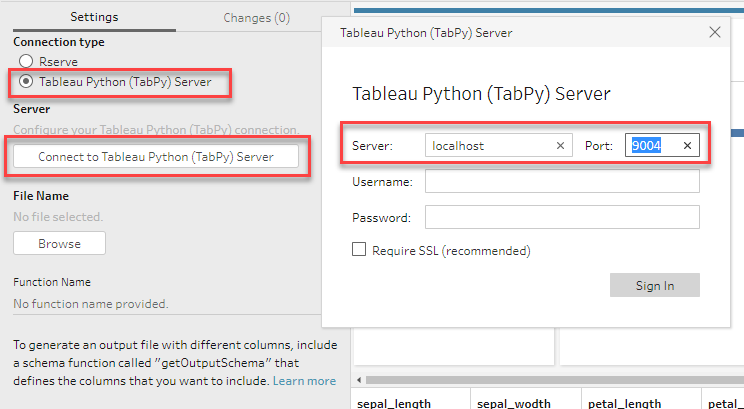
「File Name」で ”ParseData.py”を指定します。次に「Function Name」で”ParseData”を指定しますが、こちらはParseData.pyファイルで定義されたParseData()関数です。正常に設定されると、以下のように、スクリプトが実行された後の結果が表示されます。
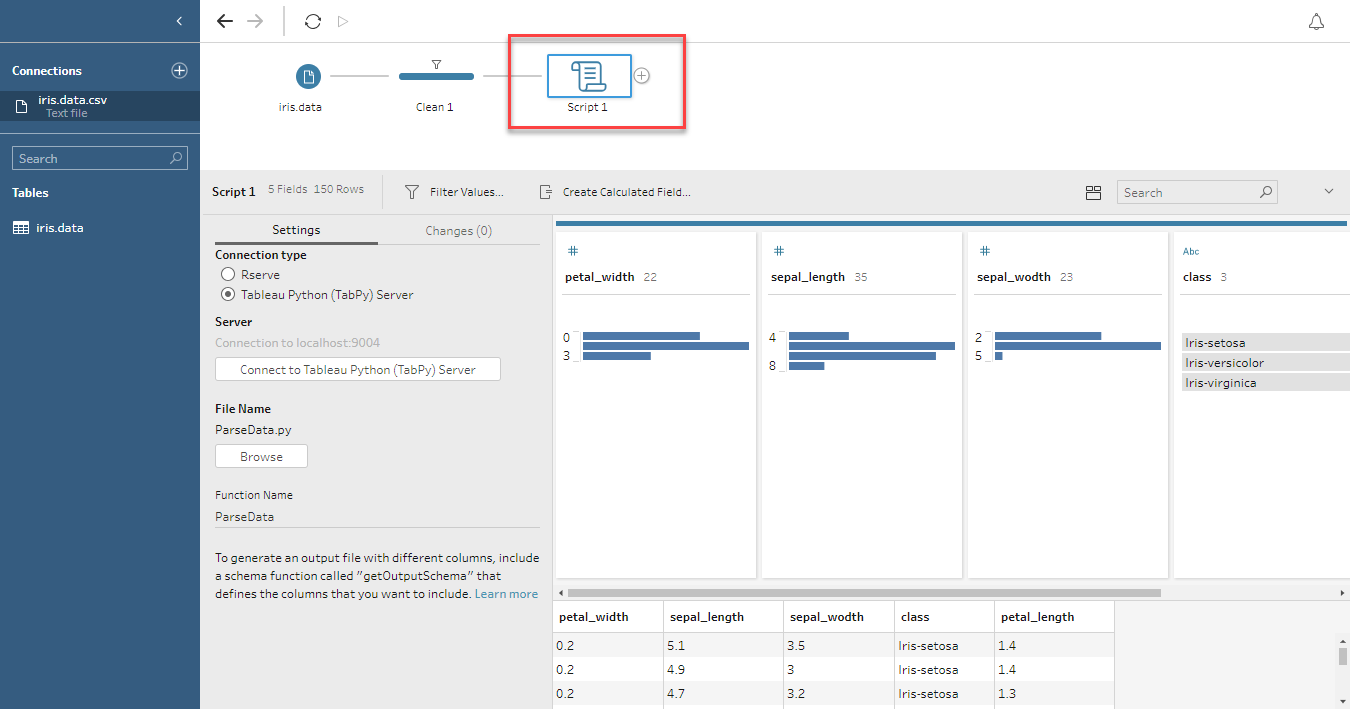
ここではただ入力をそのまま出力するだけなので、何も起こっていないように見えますが、 Tableau Prep Builder → Tabpy Server →スクリプトの実行 → 結果を受け取るという処理が行われています。ここで重要なのは、Tableau Prep Builderの前のステップの結果が”df”という名前のPandasのDataFrame(表構造のようなもの)に入れられていて、”df”というDataframeが返ってきているということです。ここはお決まりということで扱いましょう。これからこの”df”に色々な処理を加えていきましょう。
2.行番号を振る
現在のところTableau Prep BuilderではINDEX関数などの表計算がサポートされていないので行番号を振ることが出来ないのですが、これは簡単なPythonコードで実現できます。
まずはダミーで index という列を作成し”0”という値を入れておきます(後でPythonで書き換えます)。

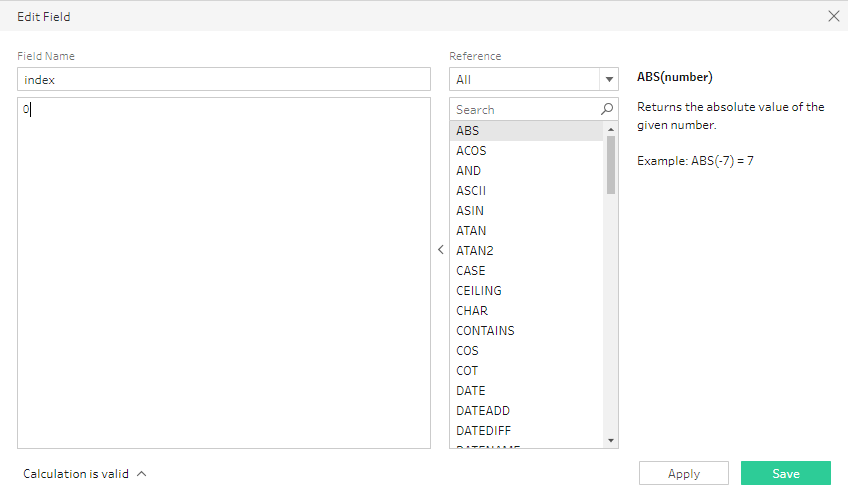
“index”フィールドには”0”が入っています。
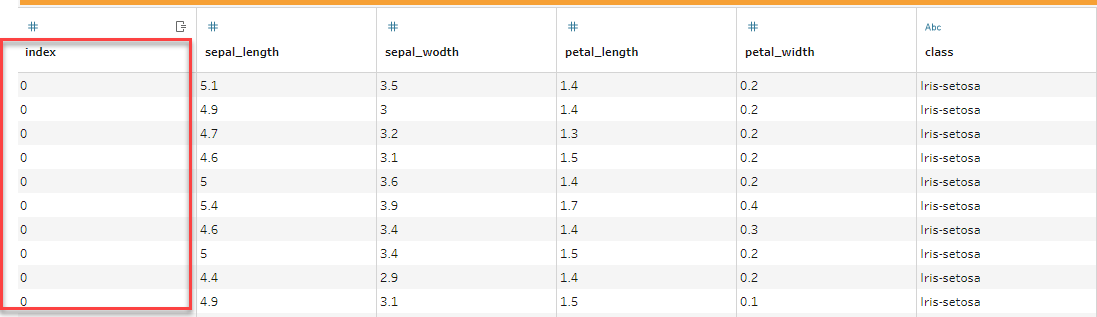
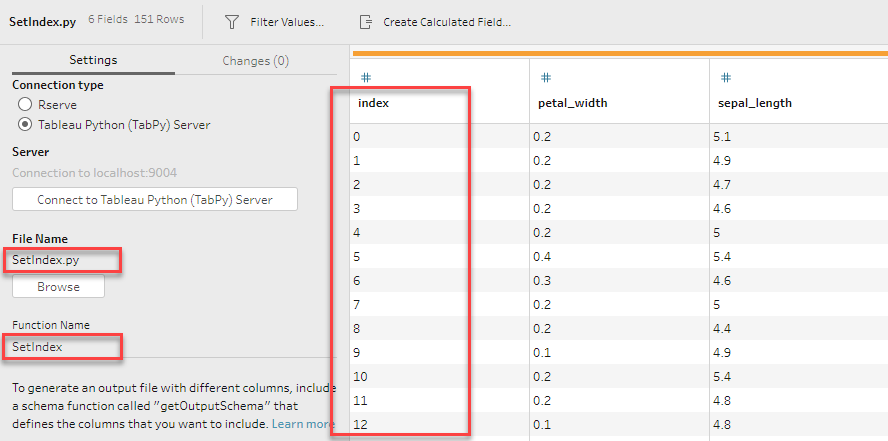
ここで、スクリプトを追加します。 SetIndex.py というファイルを以下のように作成します。FileNameにSetIndex.py、Function NameにSetIndexを指定します。

行番号が追加されています。
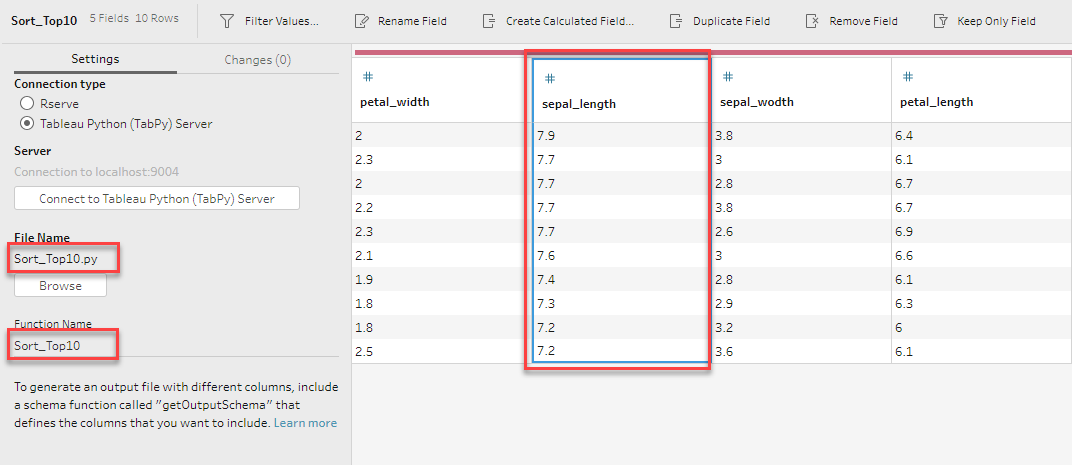
3.ソートしてトップ10を返す
次はあるフィールドでソートして上位10行を返すようにしましょう。

以下のスクリプトファイル”Sort_Top10.py”を作成します。”sepal_length”(花びらの長さ)でデータフレームを降順でソートして、更に行の 0~9 (df.iloc[:10,:] とは、データフレームの0~9番目の行、列はすべてという意味)を取る、つまり頭から10個取るということですね・・・この辺りはPython のPandas のお決まりなので、Googleで検索してみると沢山ヒットします。

”sepal_length” でソートされ、大きい順に10行取得されています。
次は重複行を削除してみます。sepal_length が同じ値のデータがありますので、これを削除してみましょう。

RemoveDuplicate.py ファイルを作成します。

同様に、スクリプトファイル名と関数名を設定します。
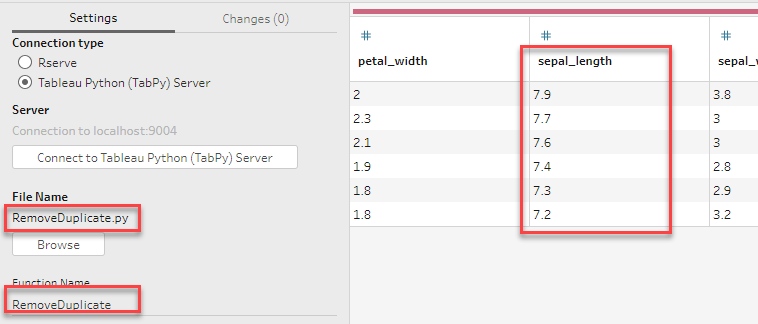
”sepal_length” はユニークになりました。この例ではあまり有効ではないですが、マスター表の顧客IDが重複する場合に重複を削除するケース等で利用が出来そうです。
4.K-meansクラスタリングを実施する
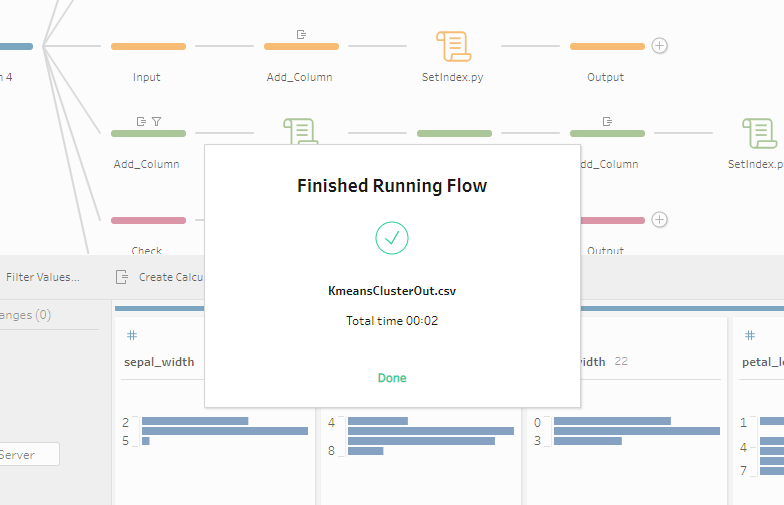
次は機械学習の基礎になりますが、Irisの花の特徴データ(花びらの長さ、花びらの幅、がくの長さ、がくの幅)からクラスタリングを実施してみましょう!最終的には以下のようなフローを作り、K-meansでクラスタリングしてIndexを付けましょう。
はじめにNULL値を除外して(除外しておかないとエラーになります)、”cluster”という列を値”0”で作成しておきます。(後でPythonで書き換えます)
次に、以下 kmeans-cluster.py ファイルを作成します。関数名は Clustering です。
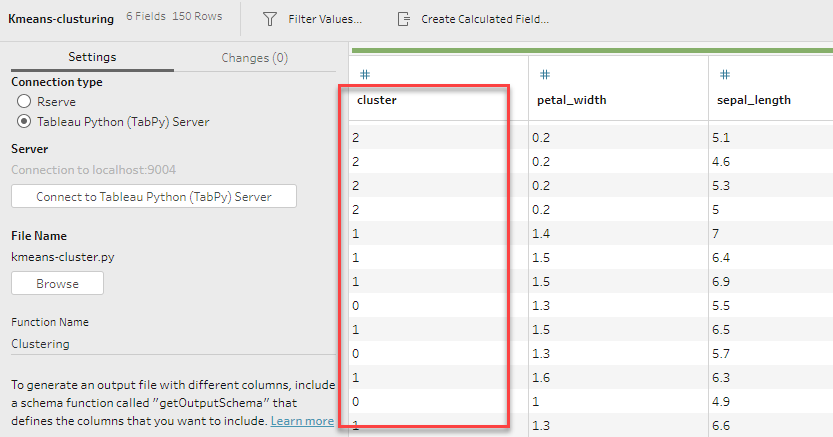
Kmeans のモデルを作り、4つの特徴量を入れて標本を3つのクラスターに分けます。分けた結果を”cluster”フィールドに書き込んでいきます。
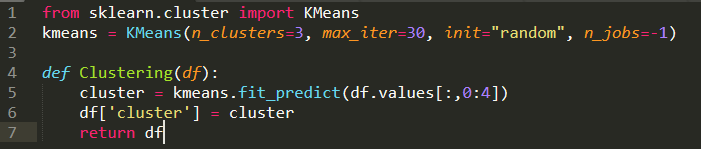
Tableau Prep Builderのステップにスクリプトを追加し関数をClusteringを実行します。
クラスタリング結果が入っていることが分かります。
K-meansクラスタリングの結果0,1,2に分類されたものと、実際の花の品種Setosa,Versicolor,Verginicaを比較して見ます。 0=Setosa, 1=Virginica, 2=Versicolor と分類されているようですね。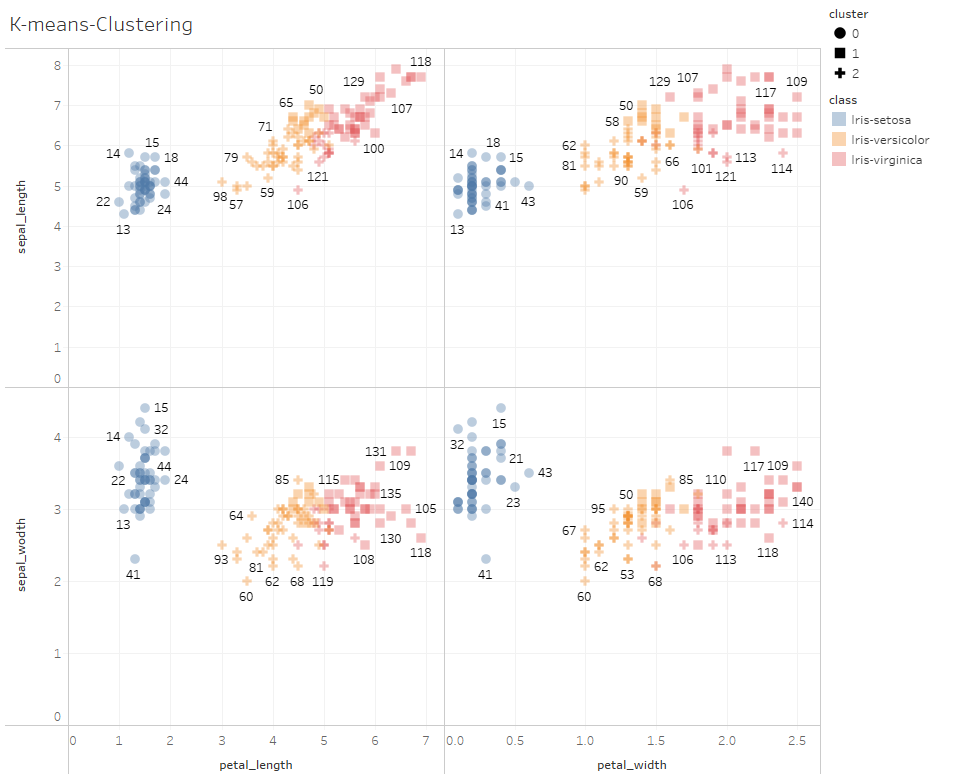
分類と合っていない標本だけ色を変えるということもできて、一部の標本についてはクラスタリングが外れていました(下のオレンジ色の標本)が、大方クラスタリング出来ています。もしかすると新種?なのかもしれませんし、ラベリング自体が違うのかも・・・ 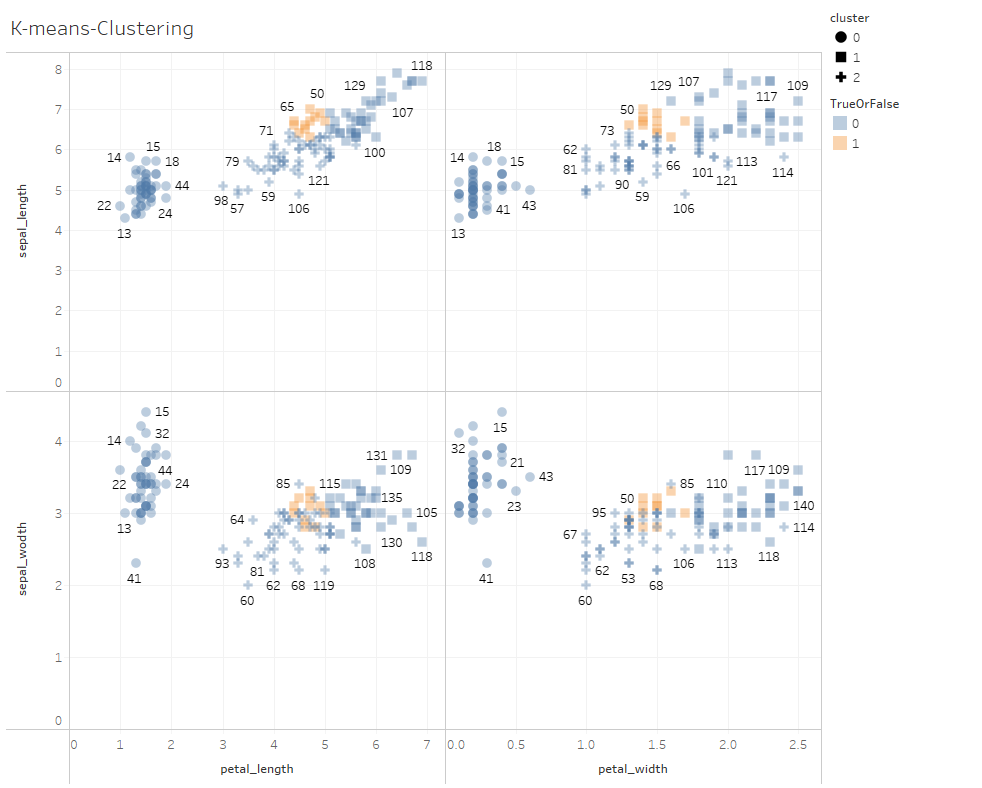
とりあえず、機械学習の基本であるK-meansクラスタリングはできましたので、モデルを作成し、特徴量をフィットさせて、学習(予測)の結果をデータフレームに追加するということはできたました。後は決定木だったり、重回帰だったり、SVMだったり、ニューラルネットだったりと同じようなステップで機械学習(予測)の結果を取得する応用ができます。
今後もう少し汎用性のある使い道を発見したら、ここから先に追加したいと思います。
以上のサンプルでは1つのファイルに1つの関数を定義していますが、もちろん1つのスクリプトファイルに複数の関数をまとめて定義することもできます。役立つ関数をまとめたツールボックスのようなスクリプトファイルも出来そうですね。
5.データベースへの書き出し (2019-07-14 追加)
データベース(MySQL)への書き出しを実施してみましょう。
*まずはMySQLにDBとテーブルを作成します。(MySQL コマンドラインより実行)
mysql> create database test ;
Query OK, 1 row affected (0.01 sec)
mysql> use test ;
Database changed
mysql> create table iris(sepal_length float(16) , sepal_width float(16),petal_length float(16), petal_width float(16), class char(16));
Query OK, 0 rows affected (0.07 sec)
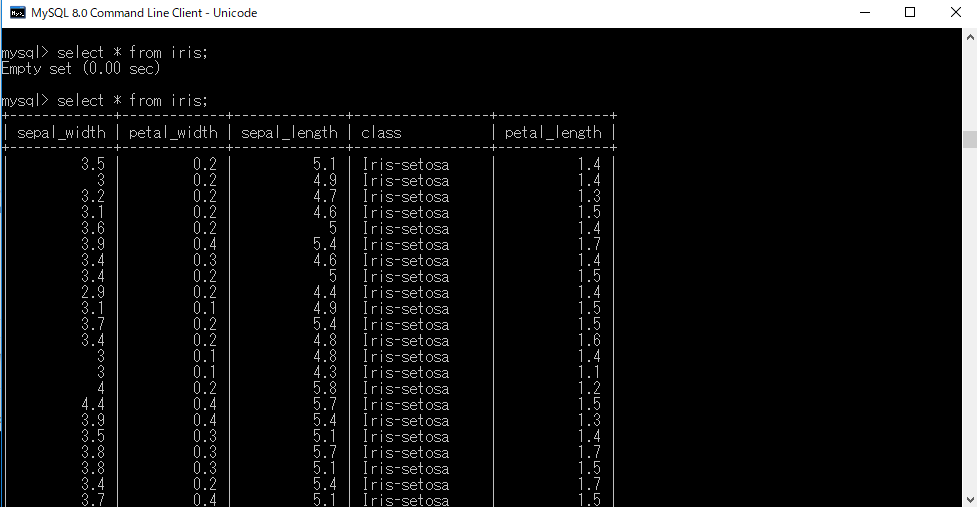
* SELECT * FROM iris ; で何もテーブルに入っていないことを確認します。
* Jupyter NotebookまたはAnacondaコマンドラインより必要なモジュールをinstallします。(Tabpy Server が起動しているAnacondaの仮想環境で実行します。)
!pip install sqlalchemy
!pip install mysqlclient
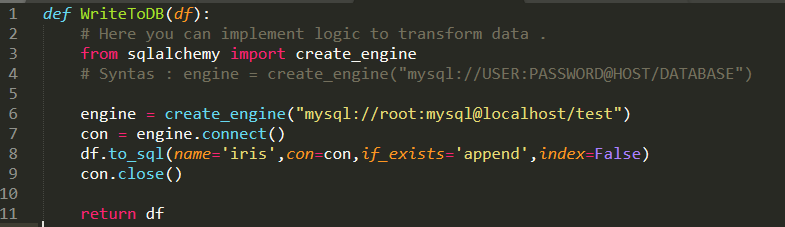
* WriteToMySql.py ファイルを作ります。
*フローから関数WriteToDBを実行させます。

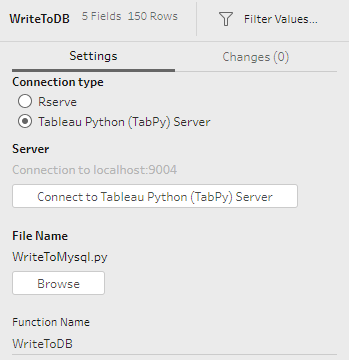
* フローを実行します。
* MySQL コマンドラインより、SELECT * FROM iris ; と打つと、DataFrame (前のステップのデータ)がDBに格納されていることが分かります。
今回利用したPythonスクリプトファイルとTableau Prep Builderのフローファイルはこちらからダウンロード可能です。
皆様も便利なスクリプトを作成された際にはこちらのポストの返信にて是非、共有ください!!
99.デバッグの方法
最後にPythonスクリプトのデバッグについて補足します。
なかなか一発でPythonスクリプトを作成してTableau Prep Builderから実行して成功するのも難しく、場合によってはエラーが出るケースもあります。ですので、以下のようにJupyter Notebookを使ってデバッグをし成功したものをTableau Prep Builderに実装するという手順を踏むのが良いかと思います。
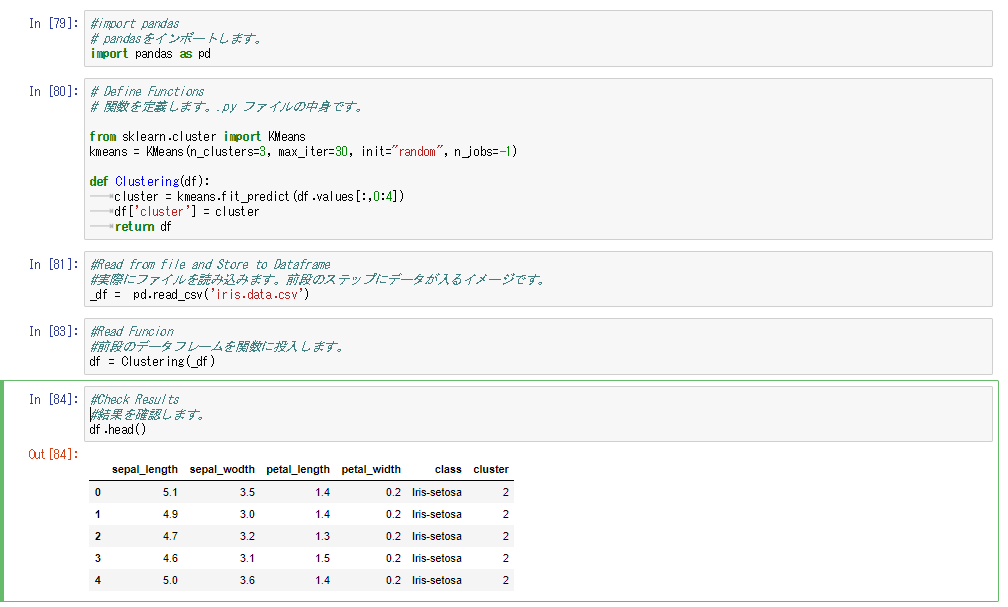
ステップとしては以下のようになります。
① まずは pandasをインポートします。
import pandas as pd
② 関数として定義する内容(スクリプトファイル)を実行します。
# 関数を定義します。.py ファイルの中身です。
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3, max_iter=30, init=”random”, n_jobs=-1)
def Clustering(df):
cluster = kmeans.fit_predict(df.values[:,0:4])
df[‘cluster’] = cluster
return df
③ ここで前段のインプットとなるデータを読み込んで一時的に “_df” に格納します。
_df = pd.read_csv(‘iris.data.csv’)
④ 前段のデータフレームを定義した関数に投入します。
df = Clustering(_df)
⑤ 結果を確認します。
df.head()
Jupyter Notebookを利用すると Shift+Returnで1つずつコマンドを実行できますので、どこでエラーが出来たか確認しながらコードを書いていくことが可能です。
皆様も是非 Tableau ベータ版2019.3 プログラムに参加頂きいち早く新機能に触れて見て頂ければ幸いです。
本記事は Tableau Zen Master: Joshua Milliganさんのブログ Python in Tableau Prep: simple useful scripts
Thomas Cristian さんのブログ TabPy + Prep == 💛 を参考に執筆させていただきました。
日本語訳を快諾頂いたお二人に心から感謝いたします。
お二人のブログも是非訪問ください!!
*** 2019-09-19追記 ***
株式会社GRIの古幡 征史さんにTableau PrepとRの連携方法についてブログ記事を作成されています。
こちらも是非ご参照ください!
This is amazing Bashii! I can’t wait to try them all!
Thank you Ciaran. Please share how you feel , new useful way of using tabpy and prep !!
My Pleasure, Larry Clark!! Thank you for reffering to my blog in yours :https://tabblogs.com/2019/07/29/using-tableau-preps-new-python-integration-to-predict-titanic-survivors/