

しかし、時系列分析では現在までのデータに加えて予測した値が追加されるので、入力と出力の数が変わってくるということになります。これをTableauで実現するためにはちょっとした工夫が必要になってきます。
今回のポイントをまとめます。
1.時系列分析では入力となる実績値のデータ数と、出力となる予測値の数が異なる
2.ダミーのデータを使ってTableauから入力するデータ数とRから出力されるデータ数を合わせる
3.Rからの最終的な出力は実測値に予測値をくっ付けて返す
です。
なんのこと?ってかんじですね。 では内容を説明していきましょう。
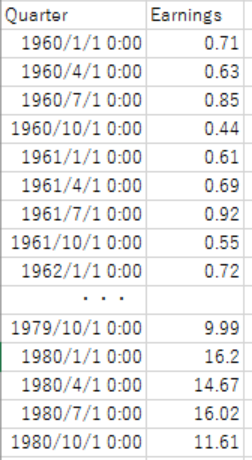
以下のような時系列のデータがあるとします。とある会社の業績データが1960 Q1 から四半期ごとに1980年Q4 まで 84 期 記録されています。
これをもとにこの先の業績を時系列分析によって予測したいと思います。
■ その1.
最初は簡単な例で説明します。
添付ワークブックの「時系列シンプル-その1」 ワークシートをご覧ください。
実データの最終ポイント 1980 Q4から先の8つのポイント(8四半期)
つまり1982 Q4 まで予測値を出してみたいと思います。
今回の実データは84個あります。これに8つの予測値を加えて最終的な出力結果は 84+8=92 個 となります。
ここで前述の通り、Tableauから入力するデータ数とRから出力されるデータ数は
一致する必要があることをもう一度思い出していただきたいのです。
そこで第一ステップとして、実データに以下のように値をNULLとしたダミーのレコードを8つ追加します。

え! データソースを変更するの?? と思うかもしれませんが、安心してください!!
ここではR連携の仕組みがわかりやすいように一時的に対応します。
(多くの場合、都度データソースにNULL値を追加するのは難しいと思いますが、この後の「その2」でデータソースを変更しない方法をご紹介します!)
実データの変動をグラフにすると以下のようになります。1980 Q4 までにデータが入っています。

パラメータから予測する期間を取得して予測値を出す計算式を作ります。

計算式の中身が何をしているのかコメントを付けました。

これをグラフにすると以下のようになります。実績値にRによる予測値を付け加えたもの、下が実績値のみです。
分かりやすいように予測値に色を付けていますが1982年Q4までの予測値がオレンジで追加されていることが分かります。

ここで今一度計算式の中で何をしているのか Rの気持ちになって考えてみたいと思います。
Rstudioのコンソールから実際にコマンドを打ってみましょう。
簡単のため、実データとして、 1,2,3,4,5,6,7,8 が入っていてその先4 つの区間を予測するということをしてみましょう。
( もちろん、 9,10,11,12 が返ってくることが予測できますよね。。。)
> library(forecast);
# forecastライブラリを 読み込みます。
※ {forecast}パッケージは計量時系列分析にまつわる様々な関数を同梱していて、主にARIMAのモデルに代表される単変量時系列データを扱います。
> .arg1 <- c (1,2,3,4,5,6,7,8,0,0,0,0)
# Tableauからデータを入力することを想定して、.arg1 にベクトルとして1~8までの値を投入します。
ここで、Tableauの入力データ数とRの出力データ数を合わせる必要があるので、末尾に4つのダミーデータを入れ
合計のデータ数を 8+4=12 とします。
> l<-length(.arg1); #入力データの数を代入
> l
[1] 12
.arg1 の長さ(データの数)は12です。
> .arg2 <- 4
予測するポイントの数を 4 とします (Tableauからはパラメータとして入れられることを想定します)
> u<-.arg1[1:(l-.arg2[1])];
> u
[1] 1 2 3 4 5 6 7 8
.arg1 から実データのみを切り出します
> n<-length(u);
> n
[1] 8
実データのデータ数をとっておきます。
> earnings_ts <- ts(u,deltat=1/4,start=c(1960,1));
> earnings_ts
Qtr1 Qtr2 Qtr3 Qtr4
1960 1 2 3 4
1961 5 6 7 8
ts()関数により、1~8のデータを 1960年1Q から始まり、四半期周期の時系列オブジェクト・データに割り当てます
ただの数列に対して、それが時系列のデータですよということを定義してあげています。
> fcast <- forecast(earnings_ts, h=.arg2[1]);
> fcast
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
1962 Q1 9 9 9 9 9
1962 Q2 10 10 10 10 10
1962 Q3 11 11 11 11 11
1962 Q4 12 12 12 12 12
forecast()関数で実際に予測を行います。予測の期間は4点ですので、
1962 Q1 から 1962 Q4 までの予測値が計算されます。
forcast関数の意味についてはこちらを参照ください
https://cran.r-project.org/web/packages/forecast/forecast.pdf
> append(u,fcast$mean, after = n)
[1] 1 2 3 4 5 6 7 8 9 10 11 12
実データベクトル ”u” の後に予測値 fcast$meanを連結します。
実データ 1~8 の後に 9,10,11,12 がついているのがわかります。
当たり前ですが、最初に予測した結果がきちんと付け加えられていますね。
この結果がTableauに返ります。
Tableauからの入力のデータ数とRからの出力数が同じですね。
■ その2.
実際にはデータソースにダミーレコードを追加することは難しい場合がありますので、
次に、データソースにてを加えずに予測値を返すテクニックを紹介します。 少しテクニックが必要です。
添付ワークブックの時系列シンプル-その2を参照ください。
以下のようなデータソースがあります。 末尾にNULLは加えていません。
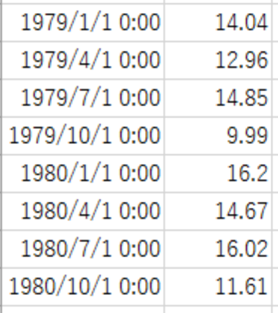
この場合に実データより先の8期間の予測値をRに計算してもらいましょう。
1.最後のデータの日付ポイントを予測期間分先延ばしにします。
計算式 ”Shifted Quarter” を作り、以下の計算式を入力します。
IF [Quarter] = {FIXED:MAX([Quarter])}
THEN
DATEADD(‘quarter’,[Num Forecast Intervals],[Quarter])
ELSE
[Quarter]
END
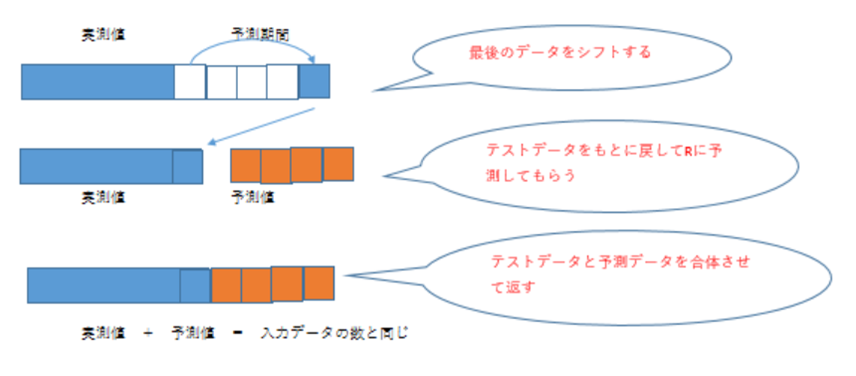
1980 Q4 のデータ 8 四半期延ばされて、1982 Q4 のデータとなります。
この最後のデータのみ予測期間分延ばされたデータをRに渡すというところがポイントとなります。
なぜこのようなことをしているかというと
TableauがRに渡す実測値の入力データとRが出力する実測値+予測値のデータ数が同じになるようにしなければならないためです。
2.実測値+Rによる予測値を返す計算フィールド ”ForcastEarnings”を作成し以下を入力します。

3.列に”Shifted Quarter”、行に”Earnings” と”Forecasted Earnings” をドラッグします
4.”Shifted Quarter”を右クリックし、”Show Missing Values”を選択します ←ここがポイント

Show Missing Valuesをチェックすることで、シフトされた末尾のデータとその前のデータの間のポイントがNULLとしてRに渡され
結果として入力と出力のデータ数が同じになります。
ここで、実測値を84個、予測値を8個と想定して先ほど作成した計算式の中のRスクリプトを解説します。
# 入力データの最後の一つ(84番目)のデータはシフトされて、予測データも含めた最後のデータ(92番目)にシフトされています。84番目から91番目はNULLで埋められいます。
l<-length(.arg1);
# 入力データの数をlに代入します、末尾を予測データ分シフトしていますから、ここでは、84+8=92 となります。
u<-.arg1[1:(l-.arg2[1])];
# u に実データ数分 (92 – 8 =84 )の数列をベクトルとして格納します。
(最後の一つはシフトされているので、NULLとなっている)
n<-length(u);
# 実データの数は84 です。
u[n]=.arg1[l];
# 実データの最後84番目のデータを92番目のデータ(シフトされたデータ)で置き換えます。
# これでシフトされていたデータが元の場所に戻り、実データのベクトルが完成します。
earning_ts <- ts(u,deltat=1/4,start=c(1960,1));
# 完成した実データベクトルu を1960 Q1 から始まる 四半期ごとの時系列データとして取り扱います。
fcast <- forecast(earning_ts, h=.arg2[1]);
# 実測値データをもとにパラメータで入力された予測期間(8) の値を予測します
append(u,fcast$mean, after = n)”
# 実測値データベクトル u に予測結果 fcast$mean を追加しTableauに返します。
ここでデータの数は実測値84 + 予測値8 =92 となります。
ちょっと、トリッキーなところはありますね。(確かに)
ただこのテクニックは、ほかの予測分析においても、入力データとRの出力データが異なる場合に使えるテクニックになりますので
応用はできそうです。
最後になりますが、Tableauには既に予測の機能が搭載されていて予測データを表示することができます。(「分析」→「予測」から実行)
ただし、Rと連携することで時系列データから季節変動要素を分離したり、ARIMAモデル以外にも先進的な時系列予測モデルを利用した予測ができたりと、
応用範囲はどこまでも広がると思われます。
その際にも今回ご紹介したTableau+R連携で時系列分析を行う際の入出力のテクニックは押さえておきたいですね。
Tableauからデータサイエンスを始めましょう!
ということで、またお会いしましょう。
bashii
参考文献
Using R forecasting packages from Tableau
https://boraberan.wordpress.com/2014/01/19/using-r-forecasting-packages-from-tableau/
完成したワークブックはTableau Community にありますのでご参照ください。
https://community.tableau.com/docs/DOC-10111