
※ はじめに: 本記事は技術的な新しい可能性を模索する目的で作成しており、紹介する内容の稼働、性能の保証をするものではございません。また、Tableau 社、及びグルーヴノーツ社の正式なレビューを受けておらず、個人的な検証結果の共有としての位置づけです。Tableau 社、グルーヴノーツ社の公式ステートメントとは一切関与がございません。
みなさん、こんにちは。今回はAI x BIの連携事例のご紹介ということで、
福岡発のAIベンチャー・グルーヴノーツ社が提供する、MAGELLAN BLOCKSとTableauを連携させて、「ネジの不良品検知ダッシュボード」を作成する過程をご紹介します。
実はつい先日、グルーヴノーツとTableau のパートナーシップが発表されましたが、→ 米Tableauのグローバルテクノロジーパートナーに認定|AIxBI でデータレイクの構築、高精度予測モデルの使用からビジュアライズまでを実現
MAGELLAN BLOCKSを利用すると、Python などのコードを書かなくとも、ブロックを繋いでいく操作で、ネジなどの「良品」と「不良品」の画像を学習し、新しく製造されたネジの画像について「良品」または「不良品」の識別を行うことができます。この結果をTableau を使ってダッシュボードにすることで、人間がアクション可能なインサイトを得られるように可視化できます。今回はその具体的なイメージをご紹介したいと思います。 まずどのようなことができるかを始めにご紹介しましょう。
まずどのようなことができるかを始めにご紹介しましょう。
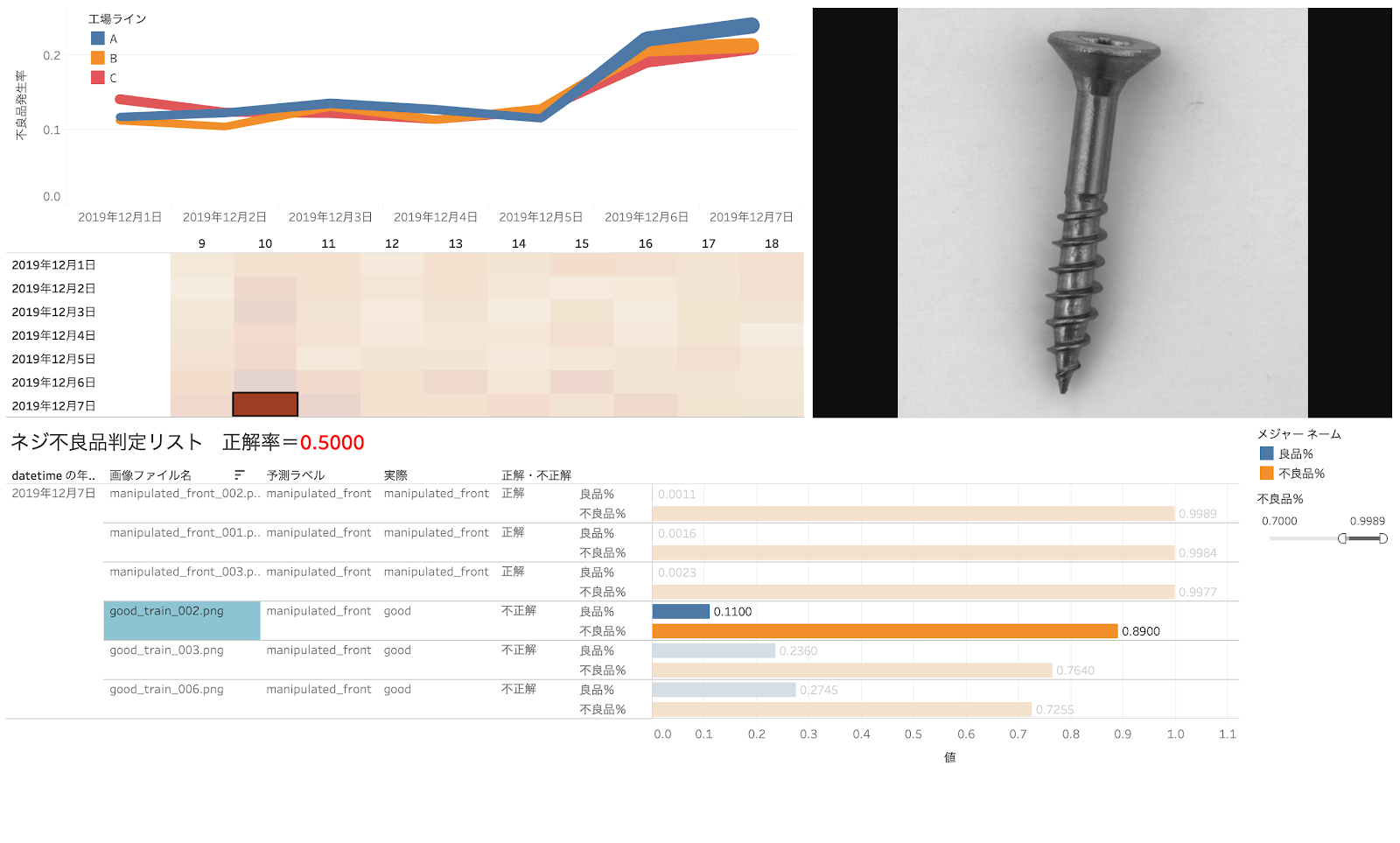
たとえば、今工場の製造ラインA、B、Cが有って、製造ラインA(青色の折れ線)の不良品発生率が他の製造ラインと比べて増加しているということが分かったとします。
更に2019年12月7日の10時に不良品発生率が高い(ヒートマップの色が濃い)ことが分かります。この時間帯をクリックすると、その時間に製造されたネジの画像リスト、MAGELLAN BLOCKSが判別した「予測ラベル」(不良品か否か)と「実際のラベル」(この場合良品・不良品は回答が出ているとします。)
リストの一番上の最も不良品確率の高い(不良品確率が 99.89% )ネジをクリックすると、その画像が表示されます。確かにネジの先がほんの少し曲がっているようです。
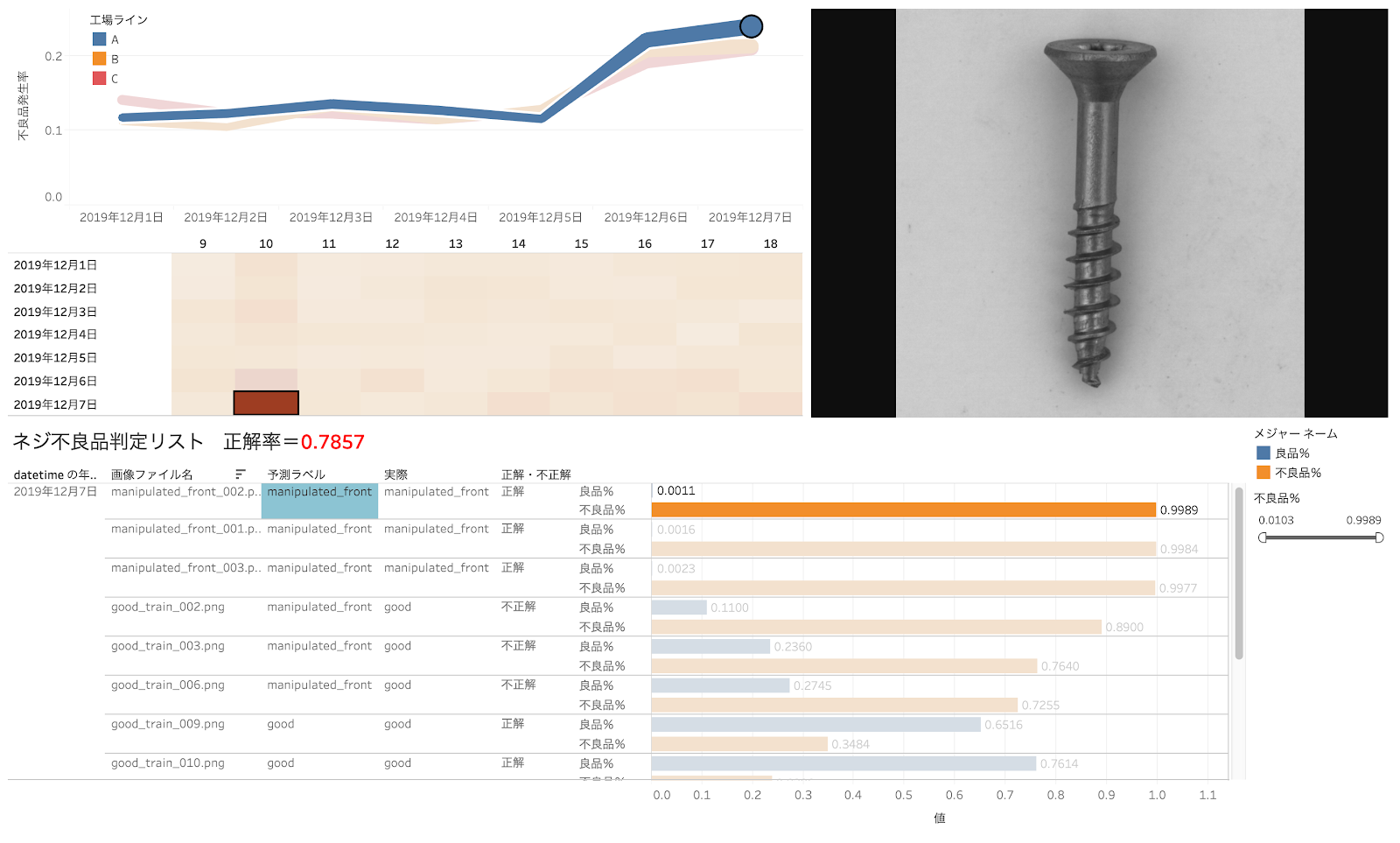
次に不良品率の高いネジ(不良品率 99.77% )ネジをクリックします。こちらは明らかに先が曲がっています。
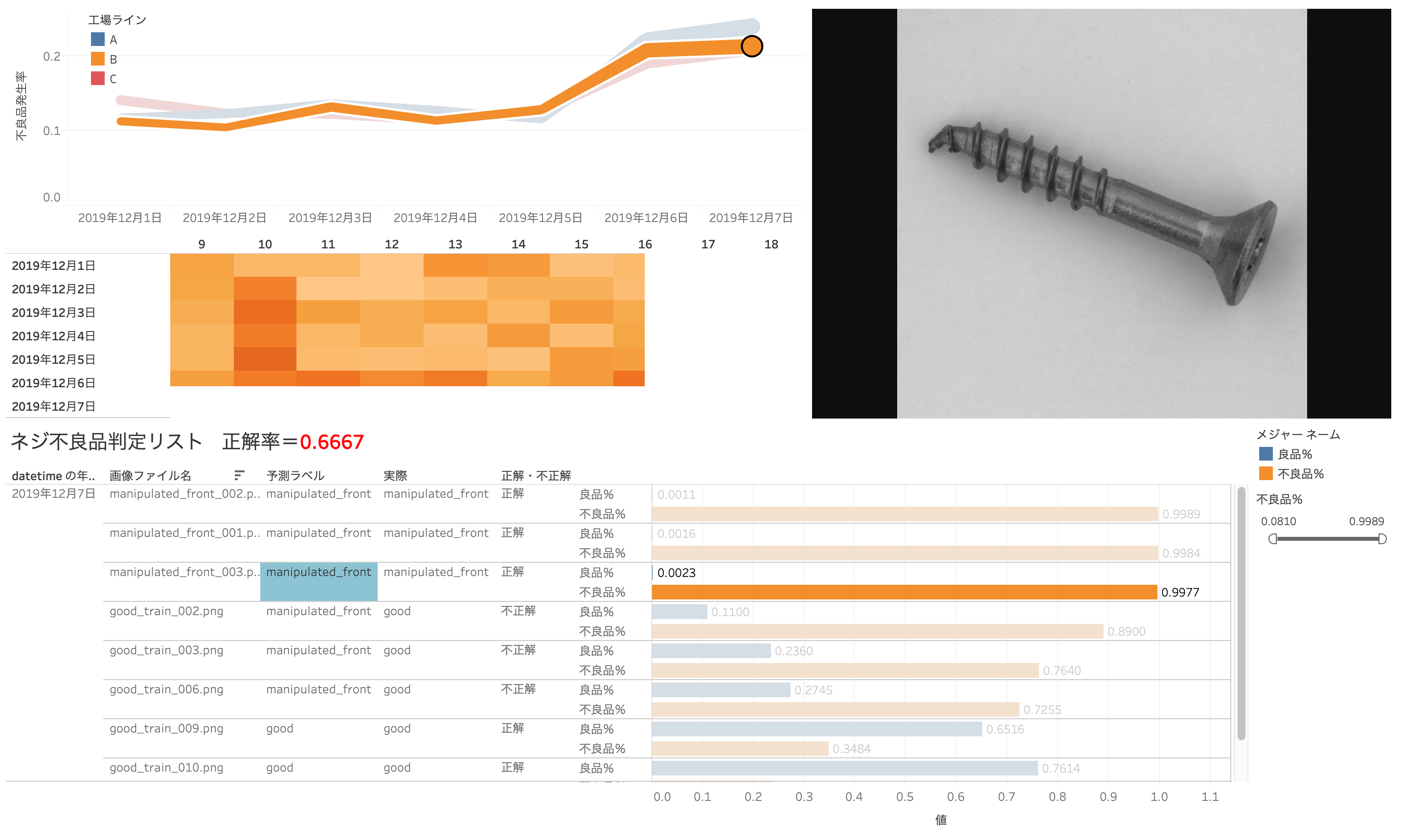
ちなみに、良品率(98.97%)のネジではこのようになります。こちらは明らかに良品です。
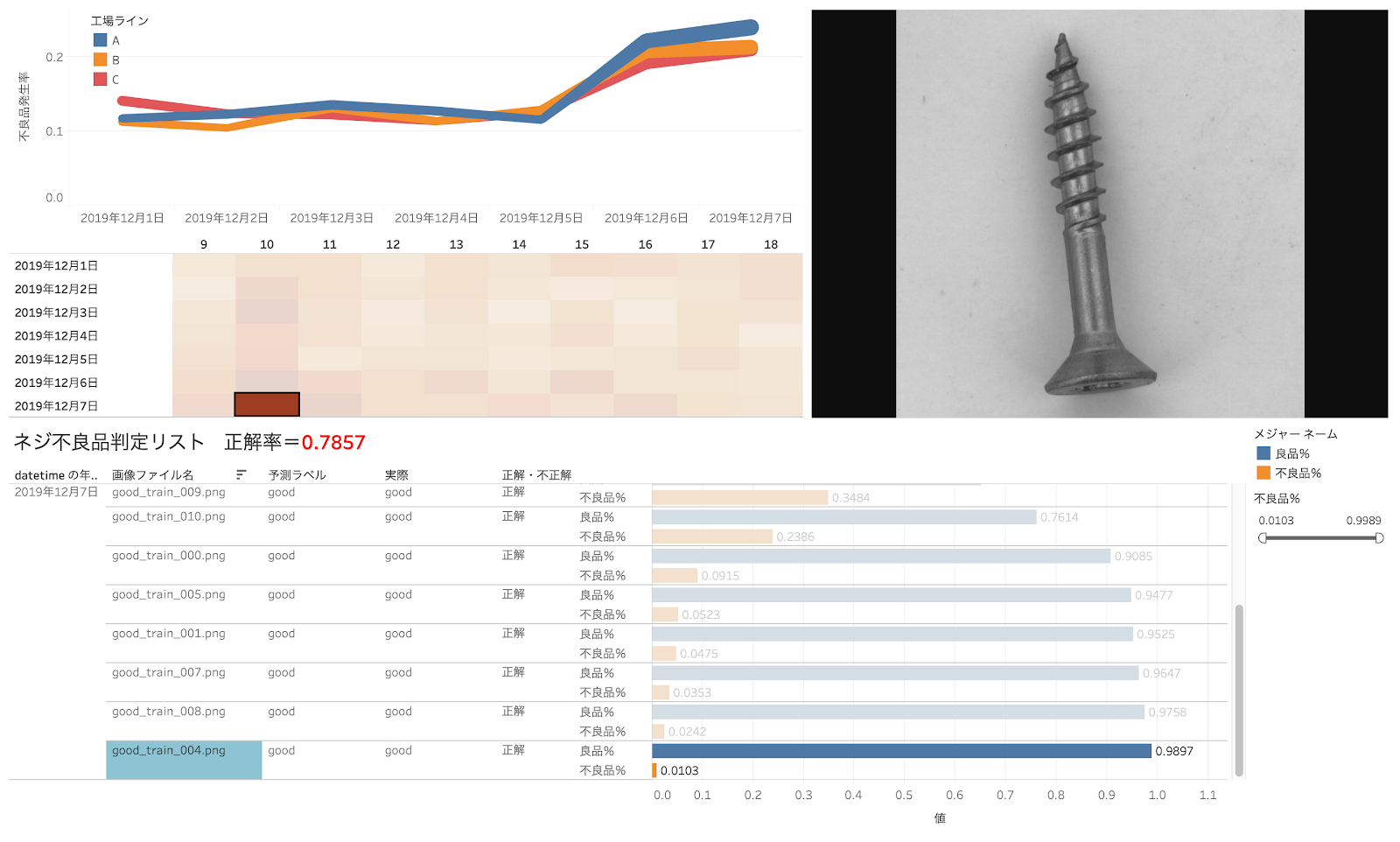
不良品率を70%以上に絞ってみるということもできます。このようにすると、人間が「良品」と判断したものでも、見逃しで「不良品」が含まれているケースを拾うことができるかもしれません。
また逆に、AIが「良品」として判断しているものでも、実は未分類の(アノテーションされていない)新たなタイプの不良品かも知れません。そういった場合、新たな「不良品」としてラベリング(アノテーション)し直してAIをより賢く教育していくことができるでしょう。
このようにMAGELLAN BLOCKSの画像認識ではじき出された不良品の確率も、Tableauで可視化することで、明確な次のアクションへと移すことができますね。
***************************
それでは次に、実際にこのダッシュボードを作成するステップを見ていきましょう。具体的には以下のようになります。
① 訓練データ(画像)を準備する
② モデルジェネレーター(MAGELLAN BLOCKS)で良品と不良品を学習する
③ テストデータ(画像)を準備する
④ フロージェネレータ(MAGELLAN BLOCKS)で不良品率を算出する
⑤ 不良品率を用いてダッシュボードで可視化する
それでは早速やってみましょう!
***************************
① 訓練データ(画像)を準備する
今回はこちらのリンク(MVTec Anomaly Detection Dataset (MVTec AD) – MVTec Software GmbH )より、個人の学習用として、ネジの良品、不良品の画像を利用させていただきました。(ありがとうございます!)
.
MAGELLAN BLOCKSでネジの良品と不良品を学習するために、訓練データとなる画像をGCS上にアップロードします。MAGELLAN BLOCKSの機能として提供される「GCS Explorer」を使うと簡単に画像をアップロードすることが可能です。

ここで、「good」のフォルダには「良品」のみの画像を入れます。
一方で「nogood」のディレクトリには、「良品」以外のすべてのタイプの不良品を放り込みます。サンプルデータでは不良品のタイプには何種類かラベリングがされていますが、ここでは「良品以外」を全てまとめるという分類の仕方によって結果的に識別の精度が上がりました。
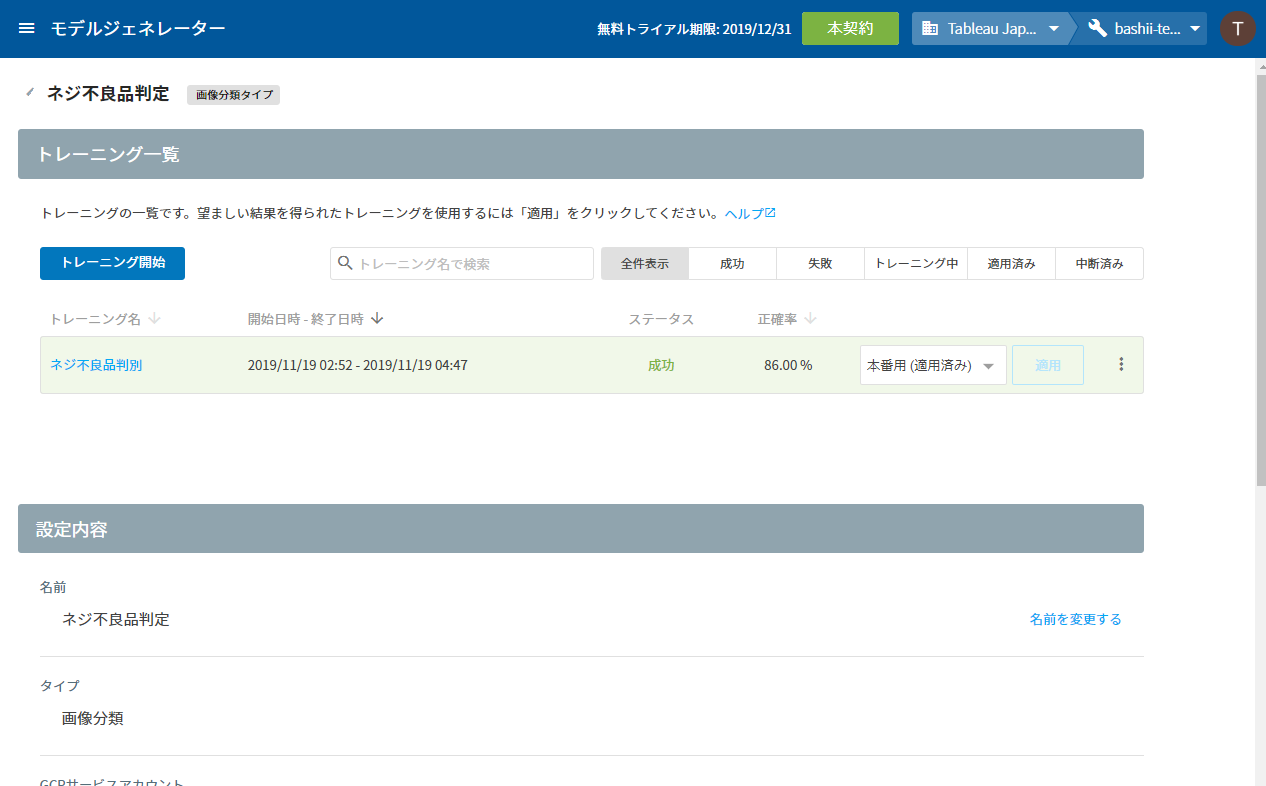
② モデルジェネレーター(MAGELLAN BLOCKS)で良品と不良品を学習する
次に、アップロードした「良品」画像のフォルダと「良品以外」の画像フォルダを指定して、MAGELLAN BLOCKSのモデルジェネレータを使って「良品」と「良品以外」の画像を学習するモデルを作成します。詳細のステップはここでは省きますが、Groovenauts,Inc.吉村さんの記事を参考にしていただければと思います。
画像による不良判定をMAGELLAN BLOCKSでやってみた
今回は訓練用に「良品」を151枚、「良品以外」を109枚準備しました。後に分かることではあったのですが、今回利用したサンプルでも「良品」の画像は大量に有りました。(実際の現場でも「良品」の画像サンプルの方が、「不良品」の画像サンプルより簡単に収集できるはずです。)しかし、「良品」のサンプル数をただ単に増やして学習させても、結果は「良品」に偏って判別される傾向になってしまったため、「良品」と「不良品」の画像数のバランスを同程度に調整するという試みをしました。また、画像サンプル数を増やすために、画像自体を反転、回転させて「水増し」をすることがあります。 詳細はこちらの記事などが参考になるかと思います。
|
Good (良品) |
Nogood (良品以外) |
|
| 訓練データ | 151枚 | 109枚 |
最終的に、モデルジェネレータによるトレーニングが完了し、学習率 86% となりました。
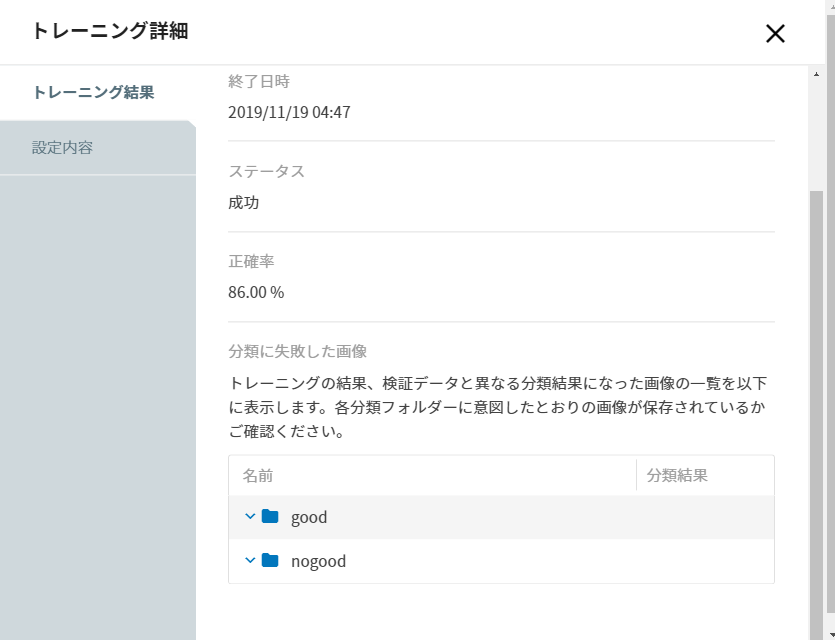
③ テストデータ(画像)を準備する
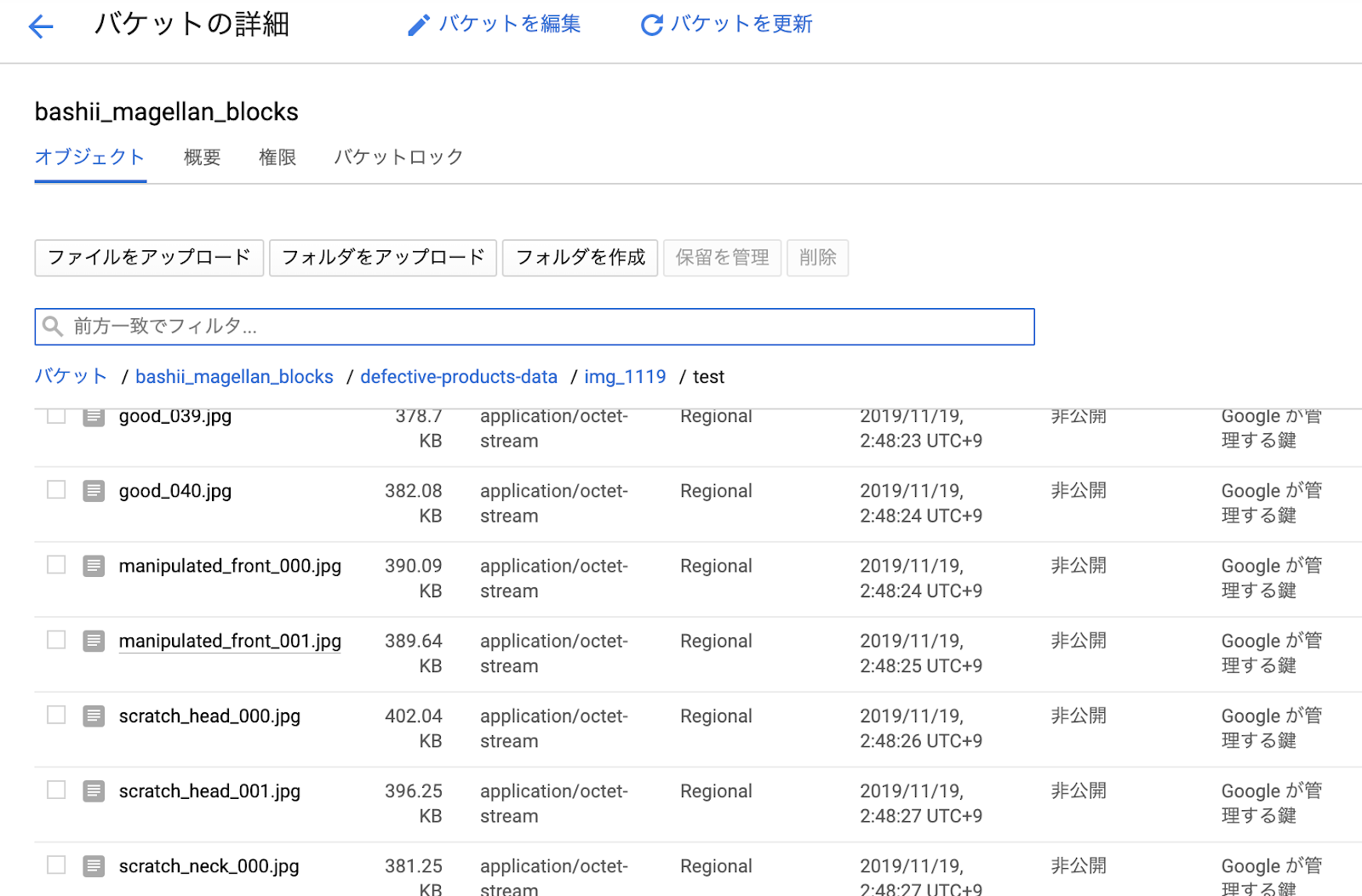
それでは次に、学習に利用していないテストデータを用いて、「良品」か「不良品」の判別を行ってみましょう。(実際には答えしての「良品」、「不良品」はラベルが付いていないはずですが、今回は検証用ということで既にラベル付けがされているものとします。ここではMAGELLAN BLOCKSの「フローデザイナー」を利用します。先程モデルジェネレータで作成したモデルに対して、テストデータの画像を与え、「良品率」と「不良品率」を確率として得ることができます。フローはテンプレートがあるので、ガイドに従って、GCS上にアップロードしたテスト画像を指定すれば、難しい操作は必要ありませんでした。
今回は、テストデータ用の画像として、既にラベルが分かっているものですが、「良品」を41枚、「良品以外」を10枚混ぜて、test GCS上のtestフォルダにアップロードしました。
|
Good (良品) |
Nogood (良品以外)
|
|
|
訓練データ |
151枚 |
109枚 |
|
テストデータ |
41枚 |
10枚 |
④ フロージェネレータ(MAGELLAN BLOCKS)で不良品率を算出する
次に、フローデザイナーからテスト画像を判別するためのフローをテンプレートを利用して作成します。今回は「画像分類予測」を選択します。あとはガイドに従って、利用する予測モデル(モデルジェネレータで先ほど作成したもの)、判別対象となるテスト画像データが含まれるディレクトリ(GCS上にアップロード済みのもの)、判別結果の出力先を指定します。
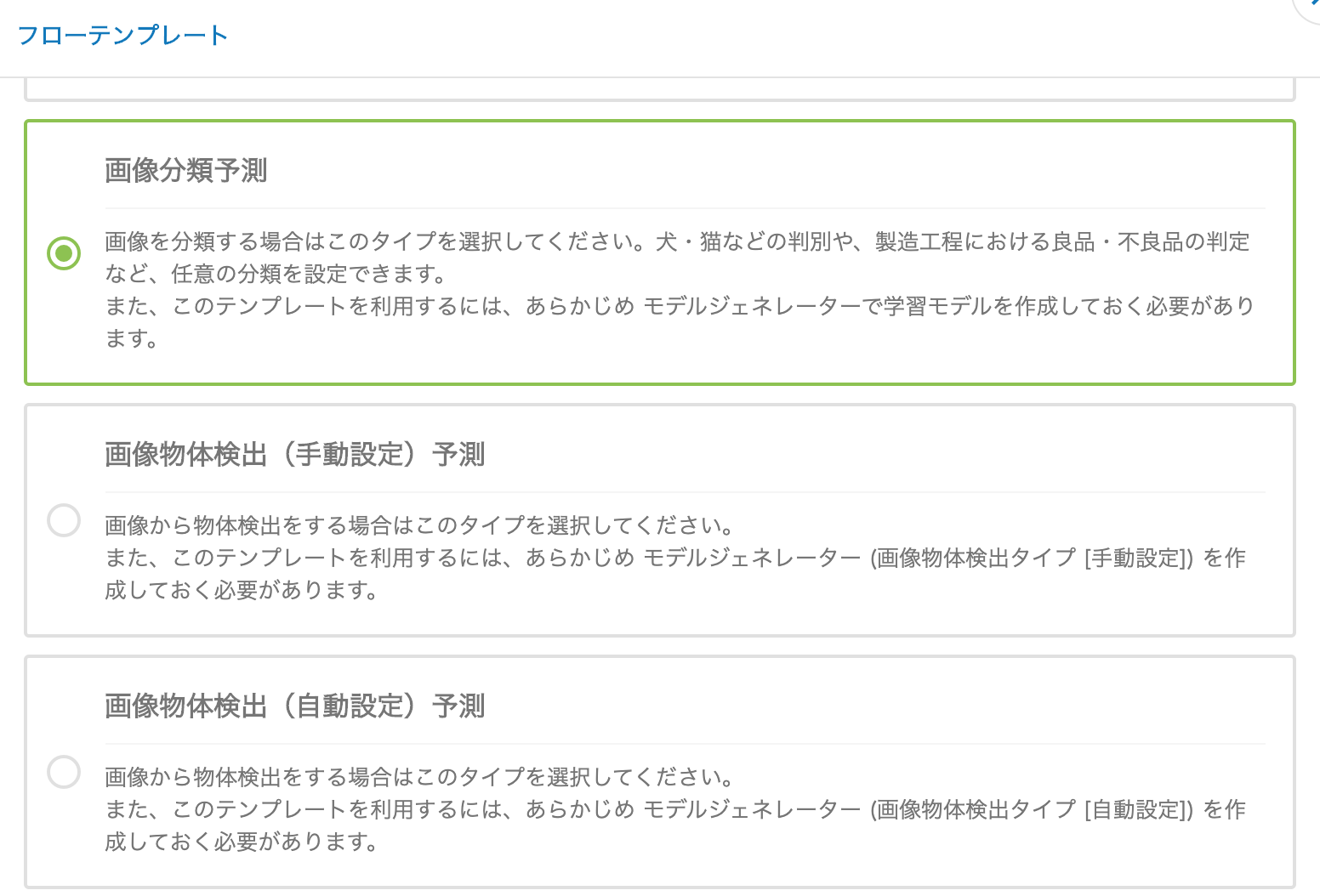
下はフローデザイナーの画面とテンプレートから作成した判別のフローです。
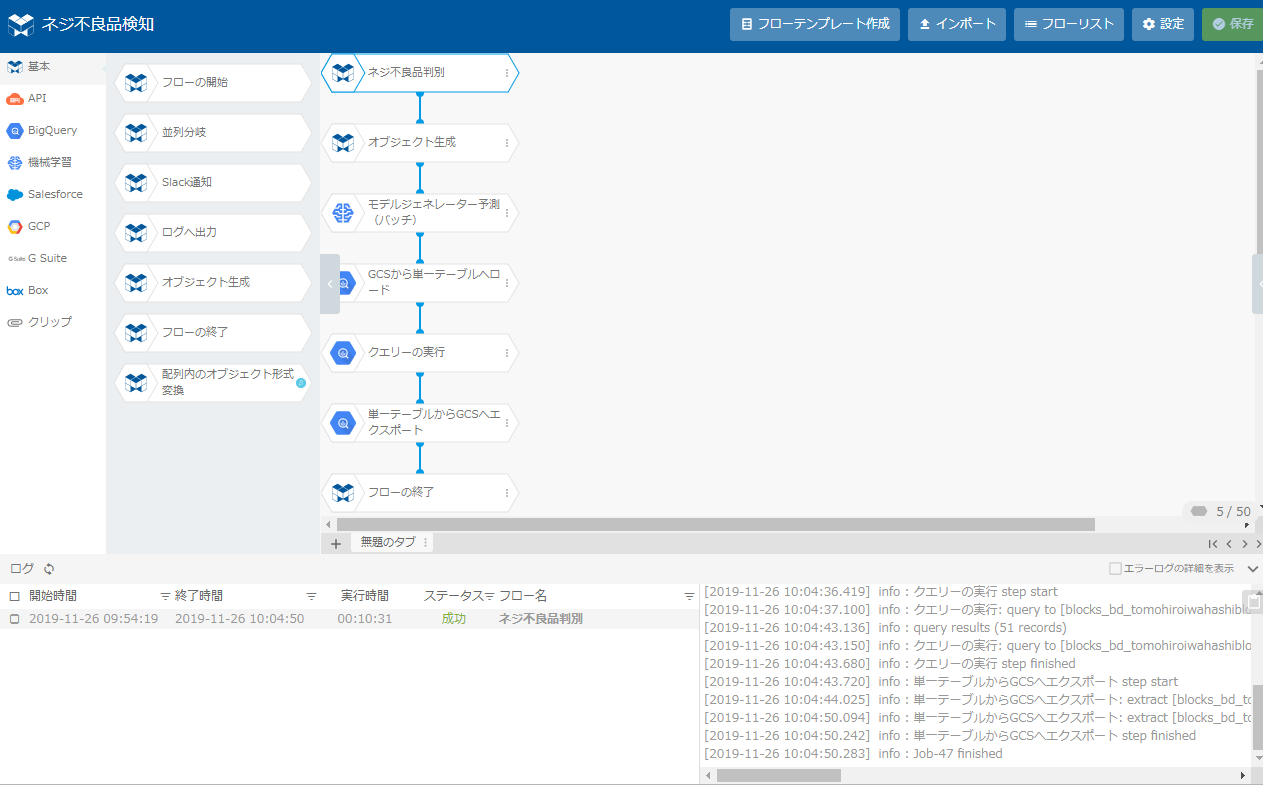
判別が完了すると、判別結果がCSVとして生成されます(今回は出力をCSVに指定していますが、Google BigQueryに書き出すことも可能です。)
↓ 判別結果がCSVで作成されているところ
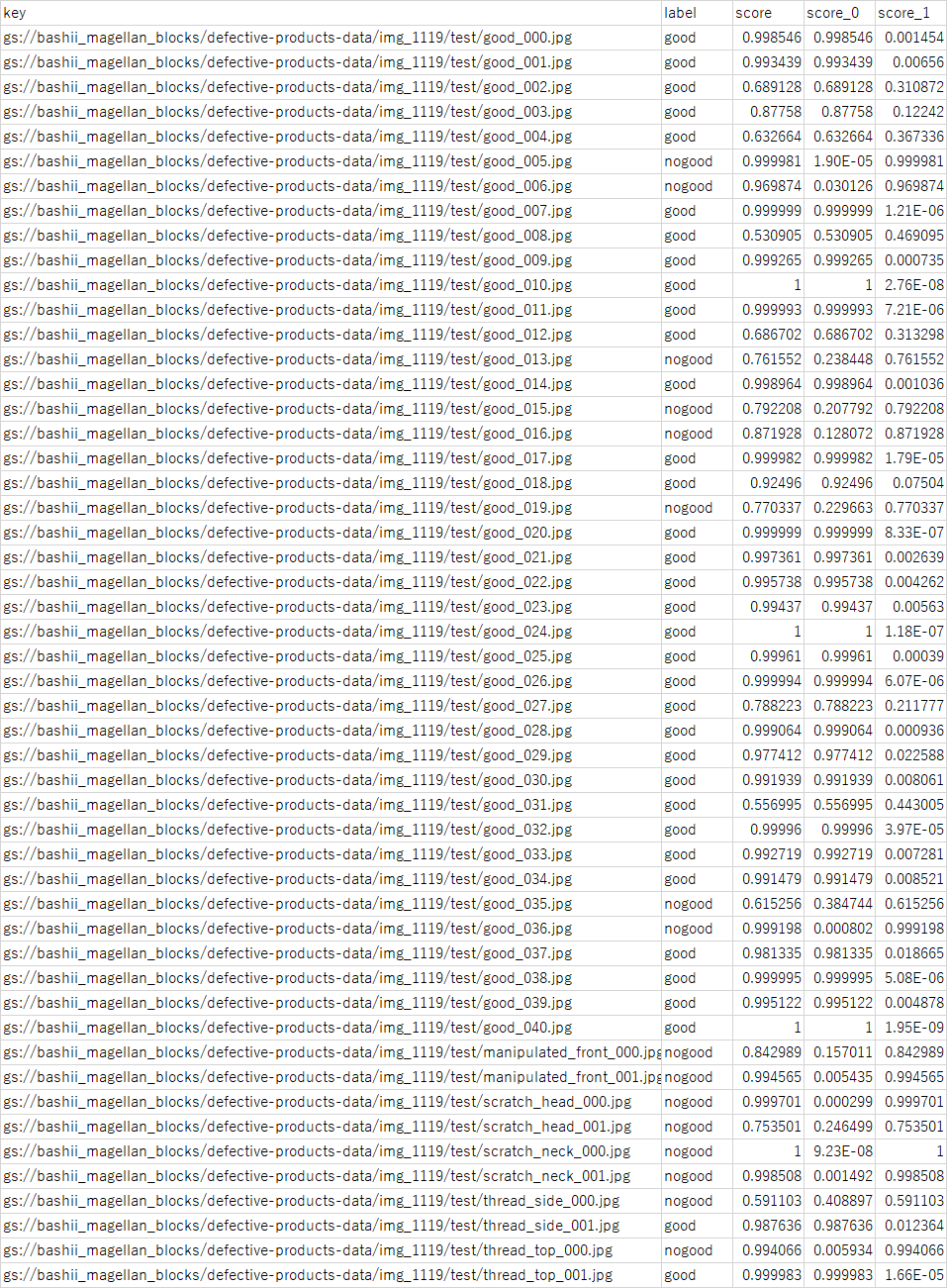
CSVの中身を見るとこのような形になっています。結果には、判別対象となったJPGファイルの場所、AIが判断したラベル、良品の確率(以下Score0)、不良品の確率(以下Score1)等の情報が含まれます。
⑤ 不良品率を用いてダッシュボードで可視化する
このままでは、さすがに人が見たときにフレンドリーなレポートでは有りませんので、Tableau を使って可視化してみましょう。
画像ごとに「良品率」と「不良品率」棒グラフで並べ、「不良品率」でソートしてみます。「不良品率」でフィルタをかければ、「不良品率」の高い怪しいネジのみフィルタすることができますね。
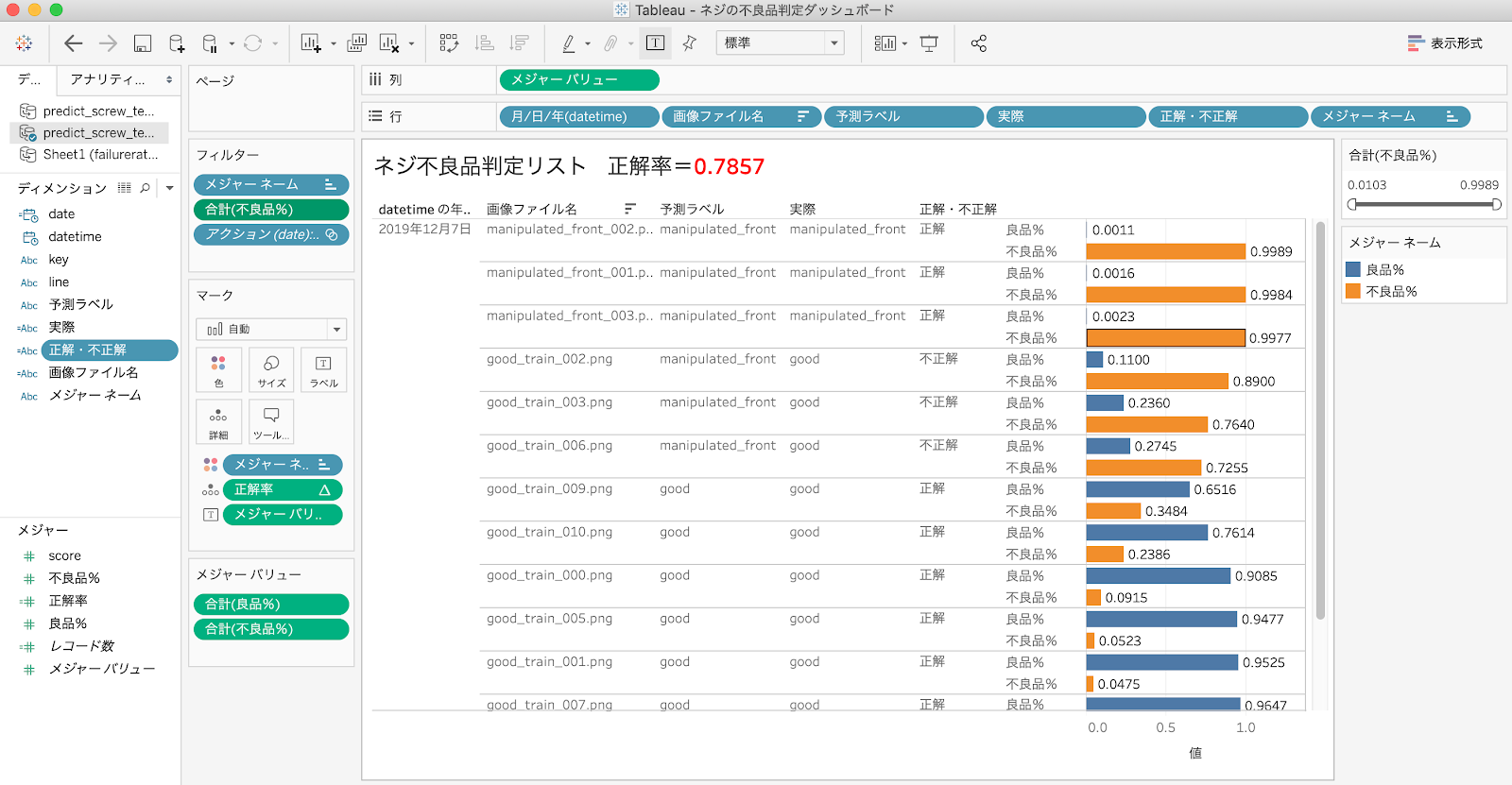
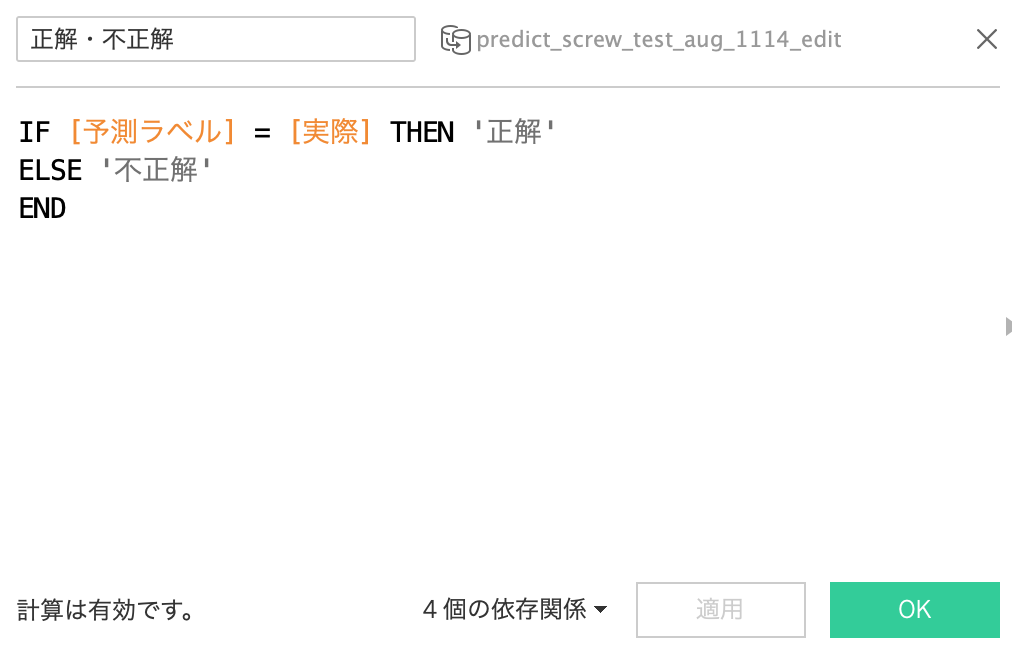
90%以上の高い確率で「不良品」と判別されるものもあれば、70%程度の微妙なものもあるということが分かります。このように微妙なものに絞って人間が再検証するということもできます。今回は結果のラベルがわかっているので、以下のような計算式をつくれば、人間が付けたラベルとAIが判断したラベルが合致しているか否かを表示できます。
次に、特に怪しいネジ部品については実際に人間の目で確認したくなってくるかと思いますが、こちらについては、ダッシュボードのWebアクションを追加し、Webサーバーにアップロードした画像ファイルにリンクを飛ぶようにすれば、ダッシュボードの中でクリックした画像を表示することが可能です。
また、どこの製造ラインで、いつ製造されたかといった情報も取得することができれば、冒頭で紹介したような形で、障害発生が多発する日時、製造ラインはどこかを発見し、更にそこで実際に製造された部品の画像を確認するといった形でドリルダウンした分析が可能になります。
最終的には以下のようなダッシュボードが出来上がります。(再掲)
§ 考察
今回の識別結果は、不良品=Positive、良品=Negativeとした場合、以下のような結果となりました。
|
|
実際Positive |
実際Negative |
|
予測 Positive |
8 True Positive(TP) |
8 False Positive(FP) |
|
予測 Negative |
2 False Negative(FN) |
33 True Negative(TN) |
*評価:
正解率(accuracy)=0.803922
※ 正解率 = (TP + TN) / (TP+TN+FP+FN) → 実際と予測の結果が有っていた割合
適合率(precision)=0.5
※ 適合率= TP / (TP +FP) 1 → Positiveと予測したもののうちどれだけ実際にPositiveだった割合
再現率(recall)=0.8
※ 再現率(Recall)=TP / (TP+FN) → 実際にPositiveだったものの中で、Positiveと予測できた割合
F値(F-measure)=0.615385
※ 2TP/(2TP+FP+FN)
より識別の精度を上げるために、1つ1つの画像を回転させたり、反転させたりしてサンプル数を増やす「水増し」や学習データにランダムにノイズを入れる「ランダムイレーシング」、特定したい障害がネジの先端部分のみの場合、先端部分以外に白抜きを入れるという方法があるということをグルーヴノーツ吉村さんよりご教示いただきました。今回は検証結果を残すところまではできませんでしたが、より判別結果の精度を高めるために今後できることはまだ多くありそうです。
最後に、MAGELLAN BLOCKSを利用すると、本当に簡単にコーディングを一切必要とせず、AIによる画像認識の訓練と判別ができていしまいます。この結果をBIから利用してより人間が見て判断できる形にすることでAIが導き出す情報をインサイトへに変え、データが持つ価値を倍増できることを実感しました。これからもAIとBIの連携に期待です!
以上、本記事が少しでも皆様の参考になれば幸いです。
追伸:
本記事の作成にあたり、グルーヴノーツ社の吉村さん、渡邉さん、金田さん、徳永さんに多大なるご支援、ご教示を頂きました。ありがとうございました。
Tableau Public はこちらです。
本記事に関するお問い合わせはスプライングローバル岩橋までご連絡ください。
どうぞよろしくお願いいたします。