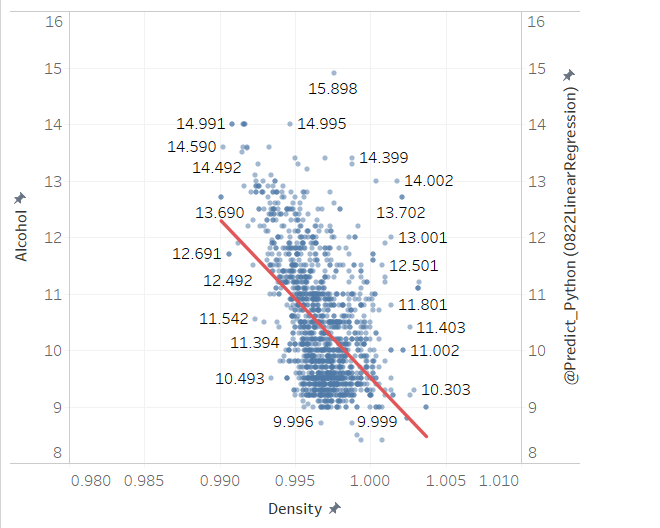
今回はTableau + Python 連携を使って線形単回帰をやってみたいと思います。
■ ボストンのデータを読み込みTableauで確認する
まず、UC IrvineのリポジトリからBostonの住宅価格に関するデータをダウンロードします。
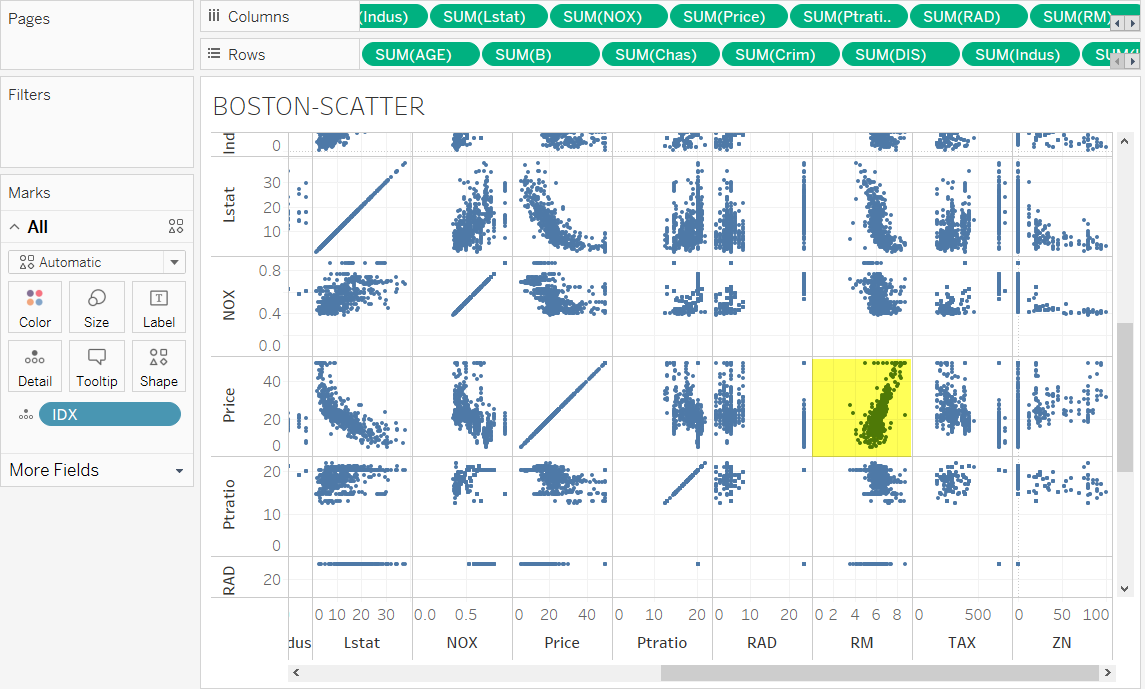
まずはTableau でざっくり可視化してデータの概要を把握します。
散布図を描いてみましょう。
どうやら住宅価格(Price)と平均部屋数(RM)がに正の相関関係がありそうです。
■ 単回帰モデルを作成し傾向線を引く
Tableau からPython のスクリプトを呼び出して、
住宅価格を平均部屋数から予測する線形回帰のモデルを作成し、予測値から傾向線を引いてみましょう。
計算式 ”@住宅価格予測Python” を作成します。
Tableau から 住宅価格と平均部屋数を入力とし、線形回帰のモデルを作成し
予測値を返します。
————————————–
SCRIPT_REAL(
‘
# Read numpy and pandas
import numpy as np
import pandas as pd
# Read sklearn.linear_model.LinearRegression
import sklearn
from sklearn.linear_model import LinearRegression
# Read data from Tableau
X = np.array(_arg1)
Y = np.array(_arg2)
X = X.reshape(-1,1)
#Fit Linear Regression Model
lreg = LinearRegression()
lreg.fit(X,Y)
pred = lreg.predict(X)
# Convert to list format and return to Tableau
return pred.tolist()
‘,
SUM([RM]), SUM([Price])
)
————————————–
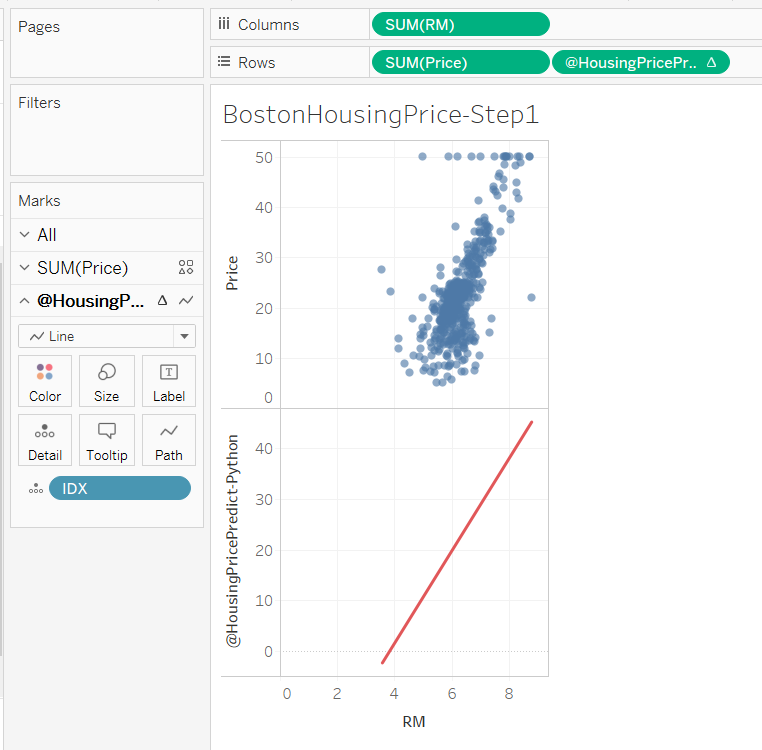
+ 平均部屋数(RM)を列に、住宅価格(Price)を行に、@HousingPricePredict-Python を行にドラッグします。
+ @HousingPricePredict-Python の表示形式を線に変更します。
+ 2重軸を設定し散布図と回帰線を重ねます。これでPythonによって傾向線をかくことができました。
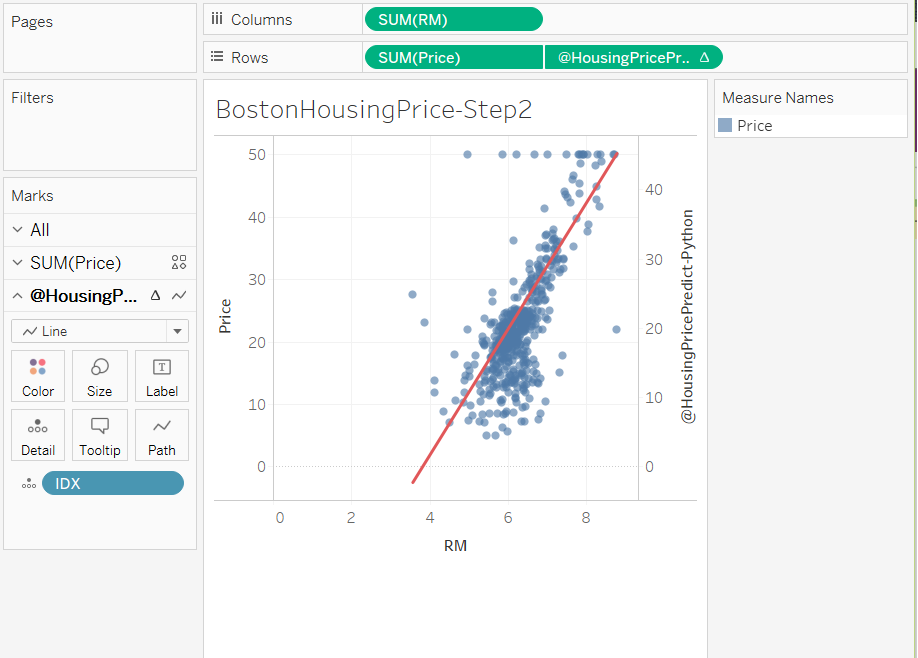
たとえば、線形回帰線から大幅に外れるデータを範囲選択してグループ化することができます。
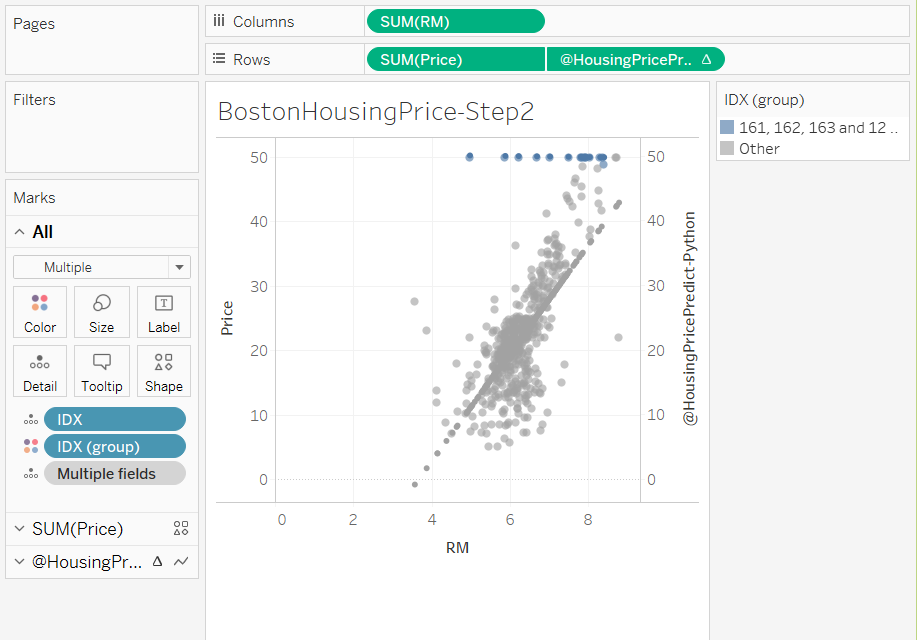
この外れ値のグループについて、どのような特徴があるのかを、散布図上で色分けして確認することができます。
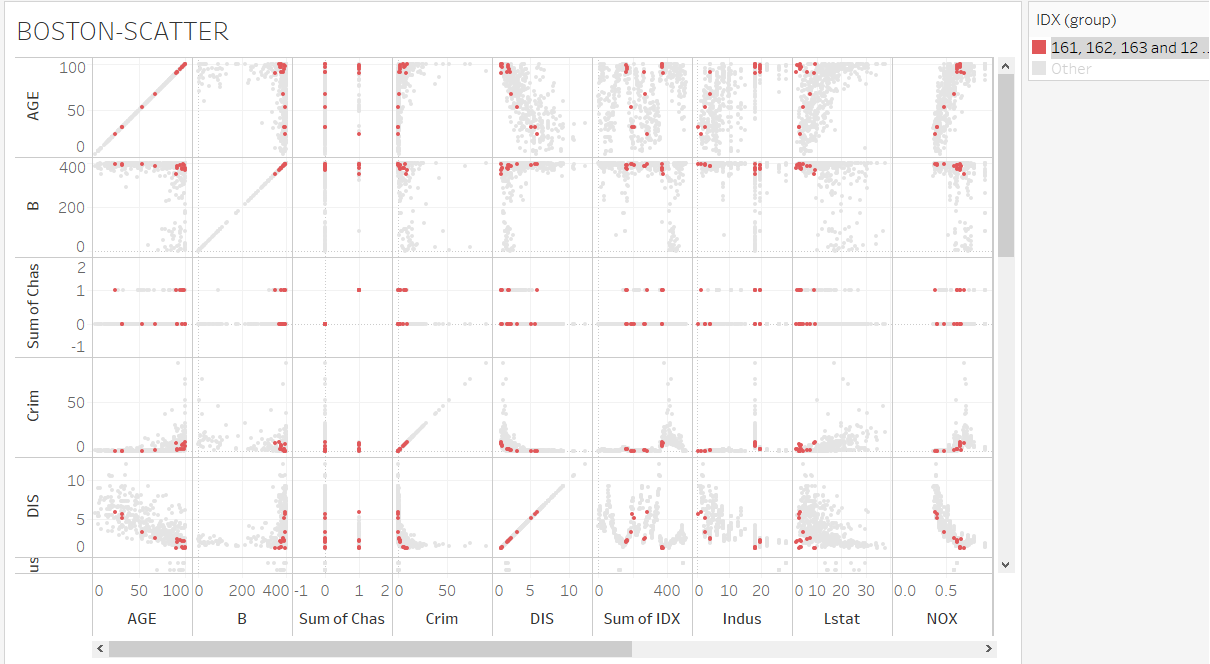
もうひとひねりして、Tableauらしさを出してみましょう。
例えばLstatを色に、Crimを大きさにドラッグしてみます。
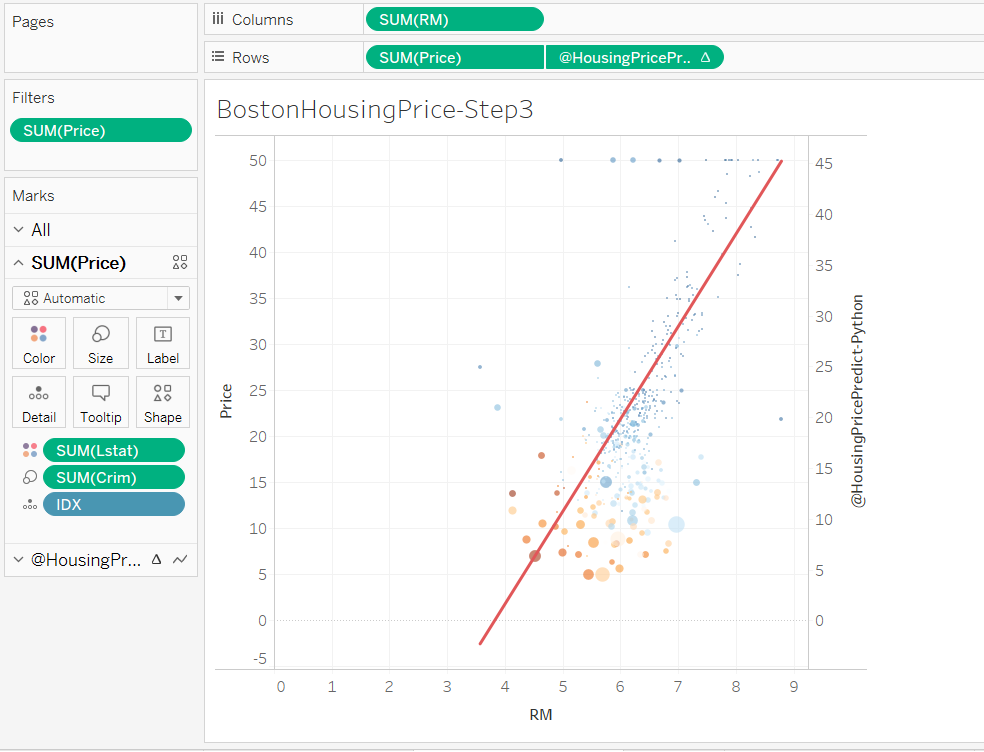
表現がより豊かになりました。大きな丸、オレンジ色の丸が左下にあることから、
犯罪率が高い地域では部屋数が少なく、住宅価格も低いという傾向が見れそうです。
Python連携を実装したTableauワークブックはこちらからダウンロードできます。