この記事は
からの続きとなります。
■ モデルの精度を確認する
データマイニングのプロセスの中でモデルを求るとき、より当てはまりの良いモデルを探していくことで精度の高い予測が可能になります。
今回は、利用する変数を入れ替えながら回帰モデルを構築し、より当てはまりが良いモデルを選択していきます。
まず最初に、前回のおさらいとなりますが:
オゾン量(Ozone)を目的変数、太陽の放射量(Solar.R)、風力(Wind)、気温(Temp)を説明変数とした重回帰分析を行います。関数としてlm()を利用します。
ここでは、こちらの記事で欠損値の保管を実施したcompleteDataを利用します。
> airquality_comp <- read.csv(“C:/tmp/completeData.csv” , header = TRUE , sep = “,”)
> air.lm <- lm (Ozone~Solar.R+Wind+Temp,data=airquality_comp)
> summary(air.lm)
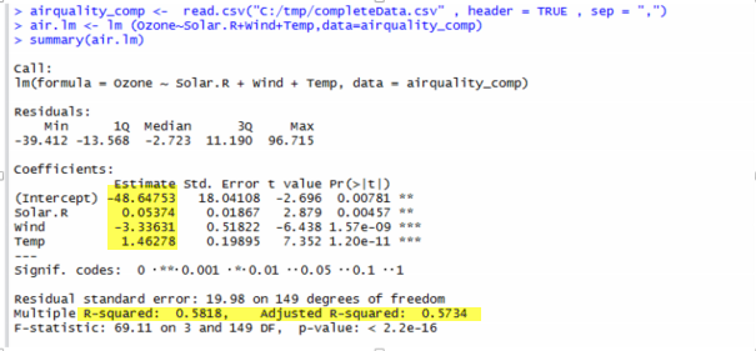
重回帰モデルの係数を確認します。
> round(coefficients(air.lm),2)
(Intercept) Solar.R Wind Temp
-48.65 0.05 -3.34 1.46
Ozone = -48.65 + 0.05 * Solar.R -3.34 * Wind + 1.46 * Temp
という回帰式が求められます。
summary を確認すると、このR二乗値(決定係数)は 0.5818、 調整済み決定係数は0.5734 となります。
決定係数とは、回帰分析によって求められた目的変数の予測値が、実際の目的変数の値とどのくらい一致しているかを表している指標で、1に近いほど分析の精度が高いことを表します。
またモデルの選択基準としてAIC(Akaike’s Information Criterion)が利用されます。
モデルのAICを求める関数として extractAIC()があります。
このモデルのAICは以下のようになります。
> extractAIC(air.lm)
[1] 4.0000 920.3784
■ 交互作用モデルの考慮
次に、交互作用モデルを考慮してより良いモデルを検証しましょう。
今までの重回帰モデルでは、目的変数と説明変数間の相関関係のみを用いていますが、データセットの中の説明変数間にも関連性がある場合があります。例えば airquarity のデータでは、風速と気温には相関関係(風速が強いと気温が下がる関係)があることが対散布図からも読みとれます。
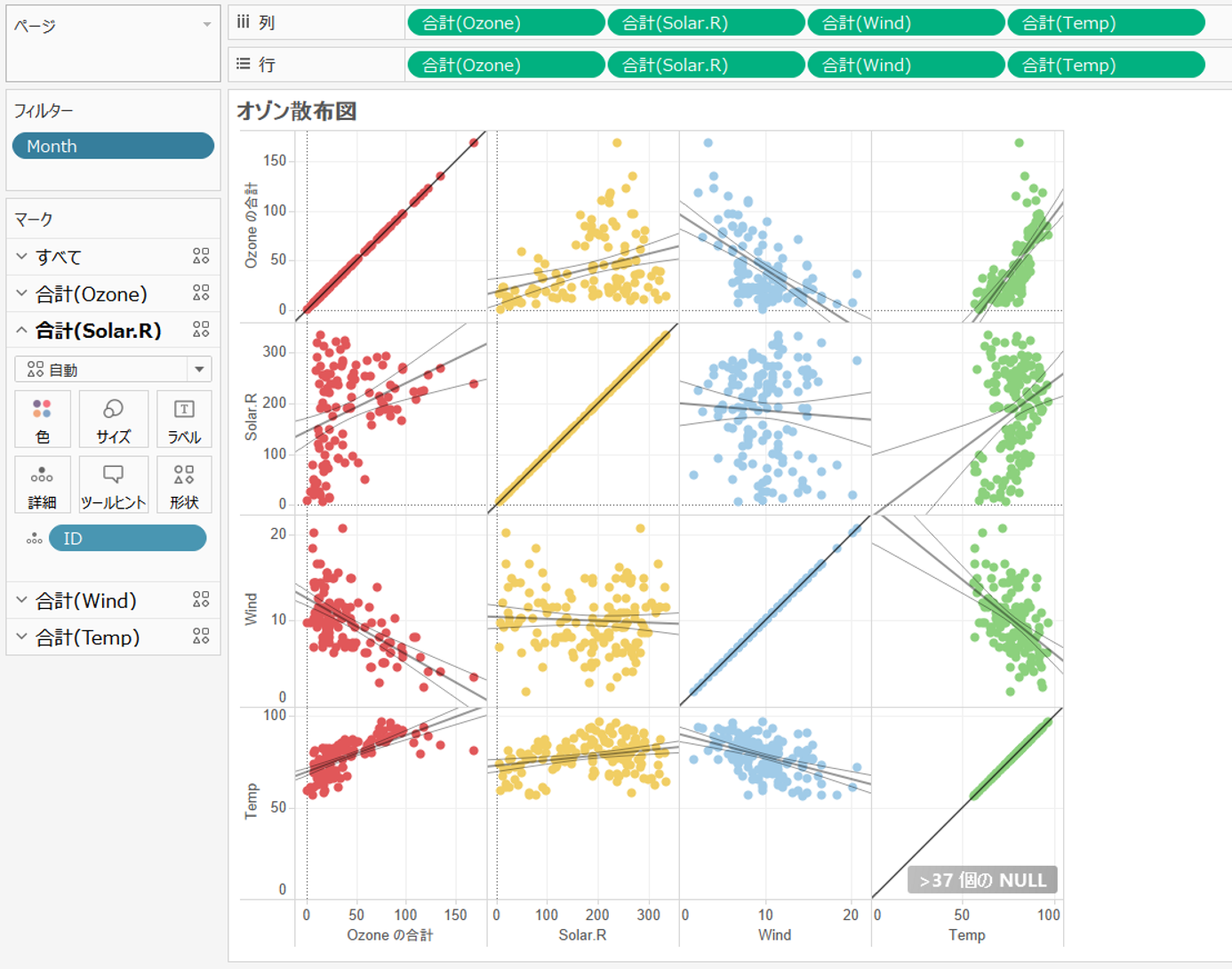
このような説明変数間の関係が目的変数に影響することを、交互作用(Interaction)と呼びます。
当てはまりの良いモデルを作成するためには、交互作用の効果を考慮することが必要となります。
説明変数が2つの場合の一般式は以下のようになります。
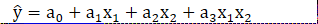
Rでは、交互作用を考慮した回帰係数を求めることができます。
以下、lm()関数のモデルの指定の中で 「^2 」を指定しています。
> air.lm2 <- lm (Ozone~(Solar.R+Wind+Temp)^2, data = airquality_comp)
> summary(air.lm2)
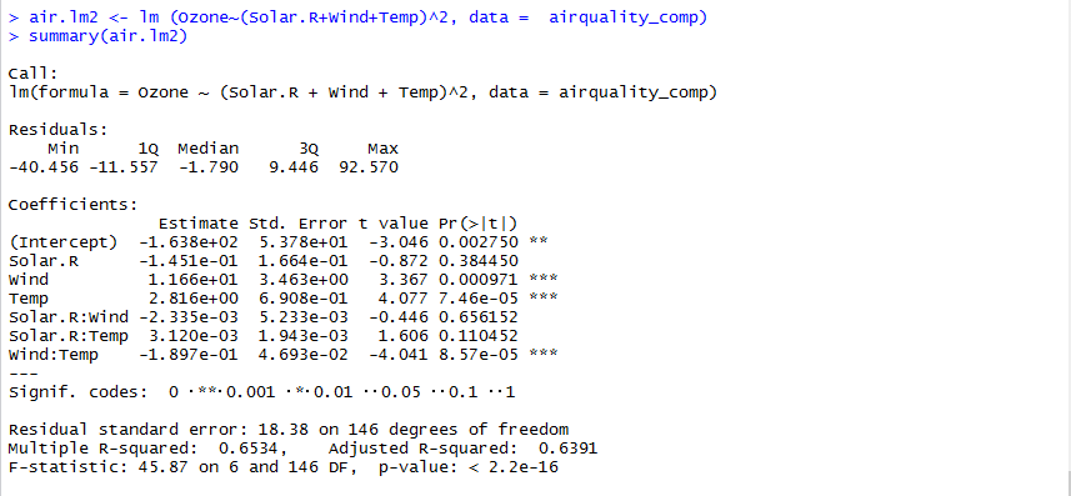
> extractAIC(air.lm2)
[1] 7.0000 897.6679
変数の数が7、AICの値が897.6679 となり、AICの値は小さくなっているので、
ちょっとモデルの精度が良くなりました。
■ step関数を用いた最適な変数の組み合わせの検証
次にAICを用いてモデル・変数を選択する関数 step() を用いてより最適なモデルを探します。
step関数を用いると、交互作用を考慮して、利用する変数を入れ替えながら回帰モデルを構築し、より当てはまりが良いモデルを導き出してくれます。
> air.lm3 <- step(air.lm2)
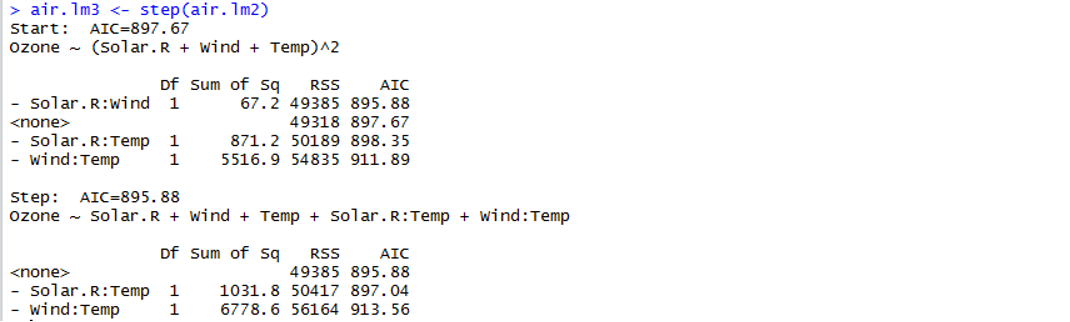
step()関数により、説明変数 Sorar.R:Wind(交互作用変数)を除くとAIC値が最も低いモデルが得られるということになりました。
> summary(air.lm3)
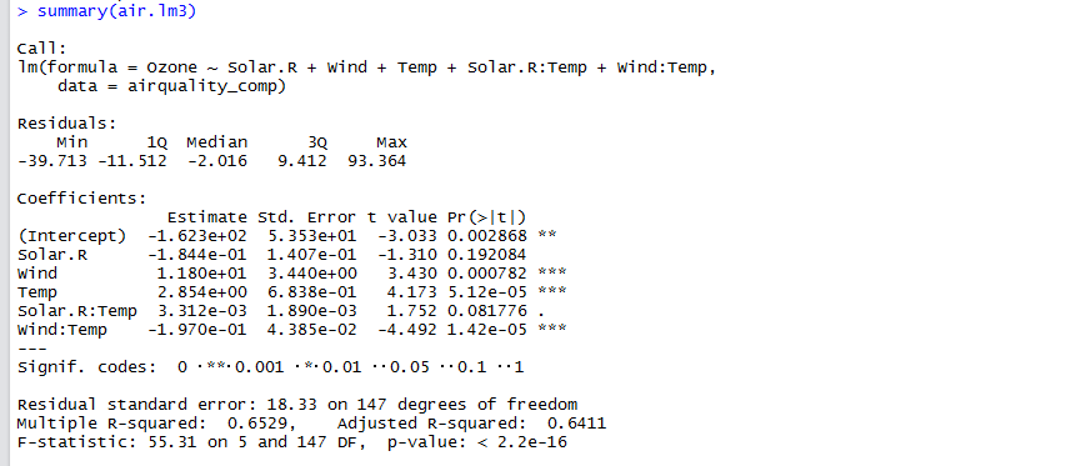
以上より、各モデルの決定係数、調整済み決定係数、AICの値は以下のようになりました。
| モデル | 決定係数 | 調整済み決定係数 | AIC |
| 交互作用なし
Ozone ~ Solar.R + Wind + Temp
|
0.5818 | 0.5734 | 920.3784 |
| 交互作用あり
Ozone ~ Solar.R + Wind + Temp + Solar.R:Temp + Soral.R:Wind + Wind:Temp
|
0.6534 | 0.6391 | 897.6679 |
| STEP検証結果
Ozone ~ Solar.R + Wind + Temp + Solar.R:Temp + Wind:Temp
|
0.6529 | 0.6411 | 895.88 |
次にモデルの当てはまりの良さをTableau を使って可視化してみるということにチャレンジしてみたいと思います。 ワークブックはこちら(lm重回帰分析_モデルの精度可視化)からダウンロードください。
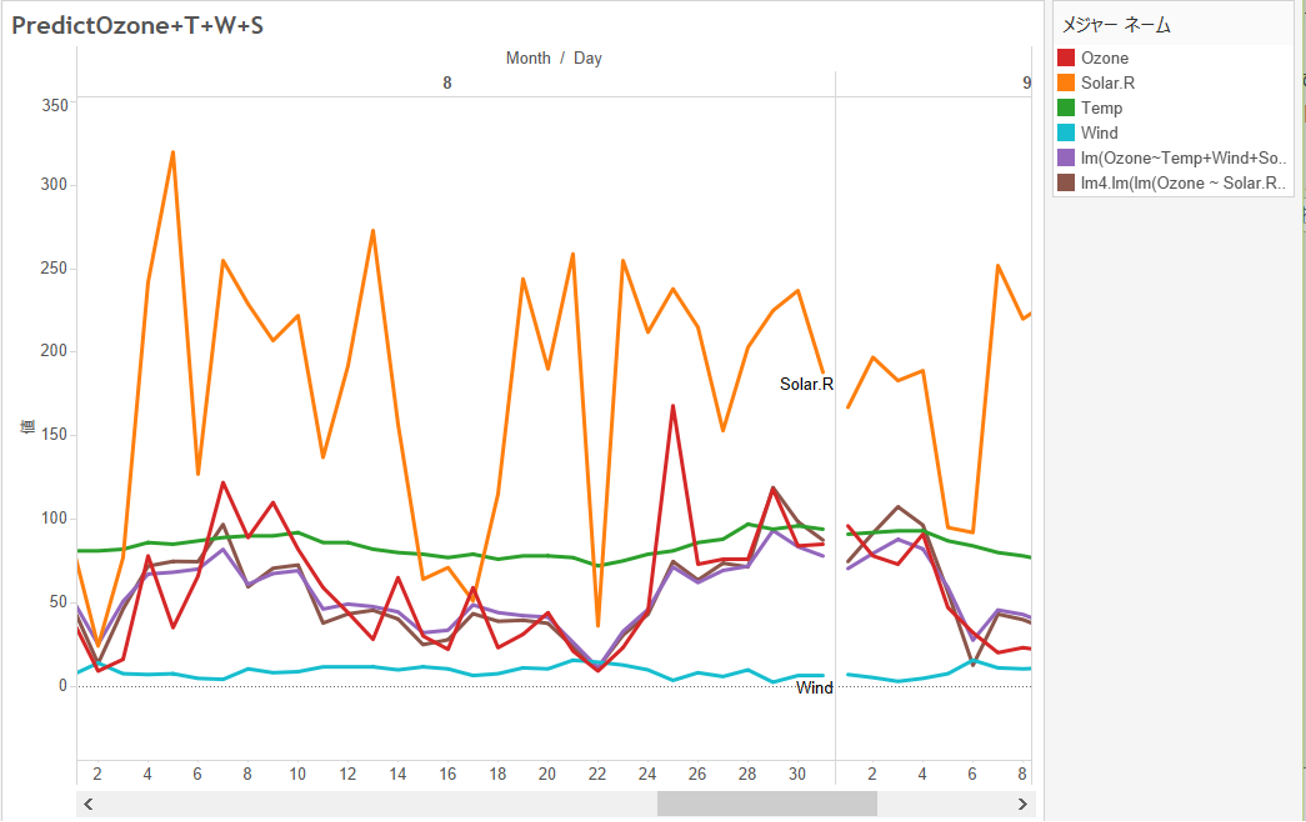
まず、作成された重回帰モデルの予測値を折れ線グラフを書いてみます。
紫色が最初のモデル、茶色がstep関数によって検証したモデルで、赤色が実際のオゾン量です。茶色の方が紫色より若干赤色に沿っているでしょうか。
これだとちょっとわかりません。
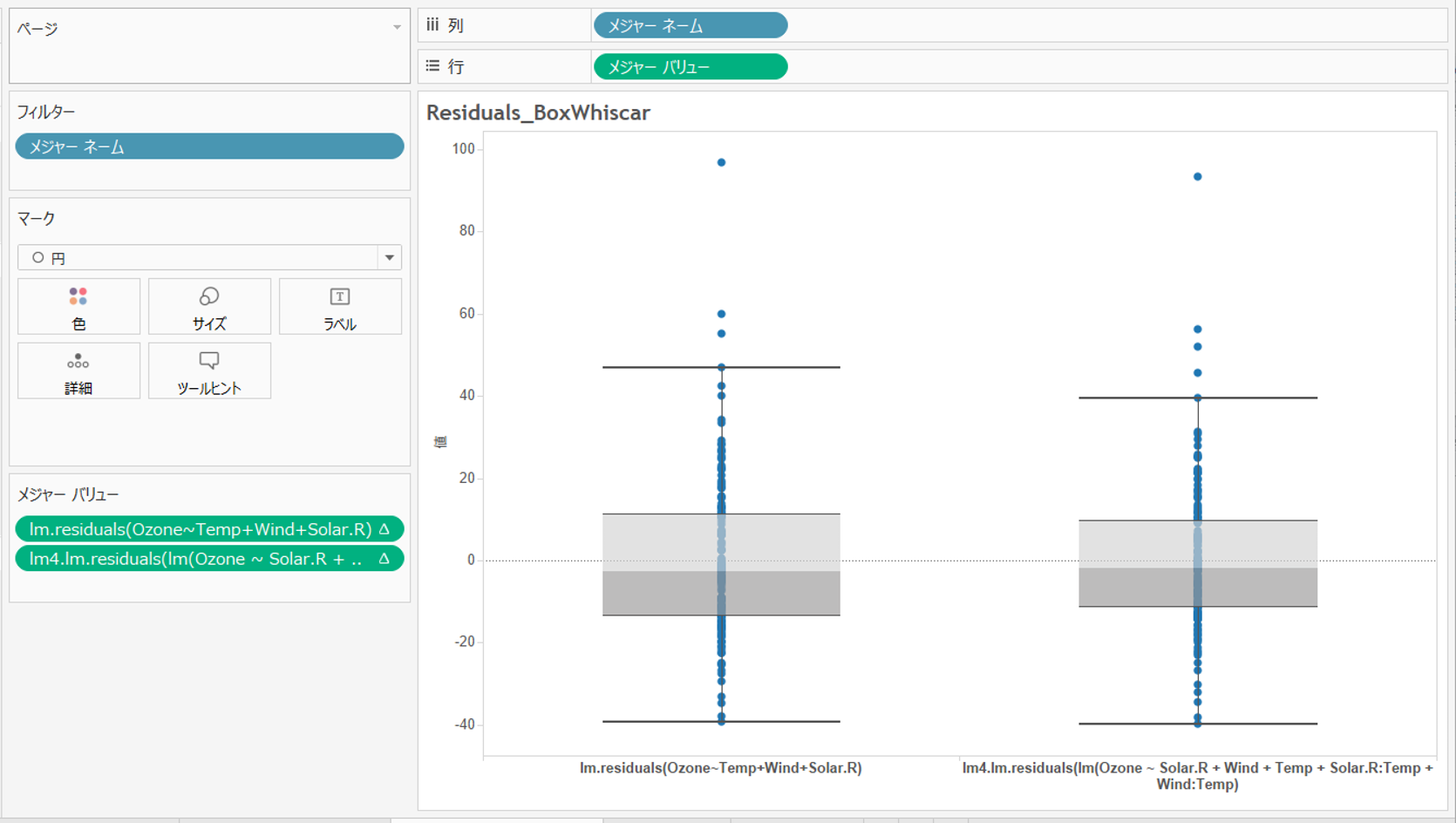
次に、残差をresidualで算出し、箱ひげ図を描いてみます。
左が最初のモデル、右がstep()関数によって精査されたモデルの残差です。
右のモデルの方が残差が0に近いところに分布しているのがわかります。
以上、より良い精度を求めてモデルを検討する作業とその可視化についてご紹介しました。