Tableau + Python 連携(Tabpy)を使ってみよう!
今回は第3弾としてPythonでより実践的なクラスター分析を実施してみたいと思います。
クラスター分析とは機械学習の一つで、与えられた標本を意味のあるグループに分類する分析手法です。ビジネスの分野でもマーケティングの戦略立案や製品ポジショニングの分析などに利用されます。クラスター分析の手法にはK-Means、DBSCAN、ウォード法による階層的クラスター分析などがあります。
図: K-MeansとDBSCANで複雑な分布をクラスタリングした例

◆ まずは、有名なiris を使ってK-measnクラスタリングを実施し仕組みを理解しましょう。今回はPythonの「Pandas」を呼び出してDataFrameを利用する必要があります。
K-Means法の仕組みについてはこちらがわかりやすいので、こちらを参照ください。
クラスタリングの定番アルゴリズム「K-means法」をビジュアライズしてみた
http://tech.nitoyon.com/ja/blog/2009/04/09/kmeans-visualise/
アイリスの花の花ガクの長さ、幅、花弁の長さ、幅の4つの指標により、得られた標本をクラスターに分類します。

Pythonでの機械学習では、DataFrameを入力としてシミュレーション結果を返すのが基本となります。
このとき、Pandasライブラリを読み込む必要があります。PandasはPythonでDataFrameを扱うために必要なライブラリです。
参考:Python Pandasでのデータ操作の初歩まとめ − 前半:データ作成&操作編
http://qiita.com/hik0107/items/d991cc44c2d1778bb82e
アイリスの花の花ガクの長さ、幅、花弁の長さ、幅の4つの指標により配列構造(DataFrame)を作り、これをインプットとして、分類されたクラスター値を出力結果とします。

今回はk-meansを使ってクラスタリングを行っています。クラスターの分類は以下の計算式を作成します。

SCRIPT_INT(
‘
from sklearn import datasets
from sklearn.cluster import Kmeans … ①
import sklearn.metrics as sm
import pandas as pd
pl = pd.DataFrame(_arg1) …②
pw = pd.DataFrame(_arg2)
sl = pd.DataFrame(_arg3)
sw = pd.DataFrame(_arg4)
d = pd.concat([pl,pw,sl,sw] , axis=1) …③
model = KMeans(n_clusters=3) … ④
db = model.fit(d) …⑤
return db.labels_.tolist() …⑥
‘,
SUM([Petal.Length]), SUM([Petal.Width]),SUM([Sepal.Length]),SUM([Sepal.Width]) …⑦
)
解説です:
① 機械学習モジュールであるsklearn をインポートします。この中にKmeansも含まれます。
② 花ガクの長さ、幅、花弁の長さ、幅の4つの指標入力をそれぞれのDataFrameオブジェクトに格納します。
③ 4つの入力オブジェクトを横に連結して入力用の新しいオブジェクトを作成します。
④ KMeansのモデリングオブジェクトを作成します。
⑤ 入力データフレームをもとにKMeans分析出力オブジェクトを作成します。
⑥ Tableauに出力する際には必ずリストオブジェクトに変換します(前回の記事で説明したお約束)
⑦ Python コードに入れるメジャーを集計関数で記載します。
花ガクの長さ、幅、花弁の長さ、幅の4つの指標入力を散布図として、得られたクラスター分類を色に持ってくるとこのようになります。標本値が似た者同士を集めて3つのクラスターに分類しています。

◆ そのほかにもクラスタリングの手法はあります!
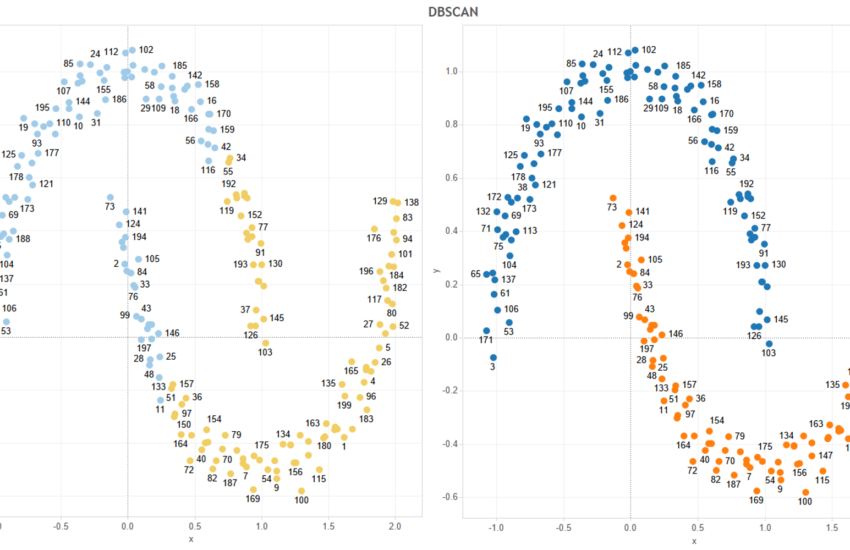
さて、次に下のように標本が球状に分布していない場合、二つの半月状のグループを意味のあるクラスターに分類する場合を考えてみましょう。人間の目で見れば一目瞭然ですが、機械にこのように柔軟な分類を実施させるのは難しそうですね。

これをK-meansでクラスタリングするとこんな感じになります。
2つの半月状のグループはうまく分別できていませんね。

ここで、DBSCAN(Density-Based Spatial Clustering of Applications with Noise)アルゴリズムを使って、クラスタリングを実施してみましょう。
DBSCANの機能についてはここでは詳しく説明いたしませんが
DBSCANは分布が球状ではない形状のクラスタリングを可能にします。K-Meansより外れ値に影響されにくいという特徴があります。 インターフェイス仕様としては、K-Means法とは違い、クラスタの個数は指定しません。
詳しくはこのあたりを参照ください
https://media.accel-brain.com/dbscan/
計算式は以下のようになります。

計算式
ーーーーーーーーーーーーーーーーーーーーー
SCRIPT_INT(
‘
import pandas as pd
from sklearn.cluster import DBSCAN
x = pd.DataFrame(_arg1)
y = pd.DataFrame(_arg2)
d = pd.concat([x,y] , axis=1)
db = DBSCAN(eps=0.2, min_samples=5, metric=”euclidean”)
y_db = db.fit_predict(d)
return y_db.tolist()
‘,
SUM([x]), SUM([y]))
ーーーーーーーーーーーーーーーーーーーーー
こちらの解説については省略しますが、DataFrameを作ってDBSCANの予測モデルに入力するところはK-meansと全く同じですね。
こちらの計算式を使ってクラスタされた結果を色にドラッグして可視化します。
DBSCANアルゴリズムを使ってきれいに2つの半月がグループ分けできました!!

◆ このように、Python と連携することで、K-means以外にもDBSCANといったアルゴリズムを使ってクラスタリングを実行し可視化できることが分かります。そのほかにも様々なアルゴリズムを利用することができるので、TableauとPython 連携の可能性は広がります。
もちろんPythonによる可視化もではありますが、例えばクラスタリングされた標本の標本IDや詳細情報もTableauだったら、マウスをホバーすれば一発で分かります。
特定の特徴のある標本をフィルターする際も、フィルターをドラッグアンドドロップするだけでプログラムを書かずにインタラクティブに実施できるので、データサイエンティストや分析担当でなくても自由にデータを探索できるのがTableauの面白いところですね。
今回紹介したDataFrameを作ってシミュレーションモデルに入れる動作はどのようなアルゴリズムを使う場合でも基本となりますので、応用いただけるかと思います。
Python が提供する様々な機械学習、深層学習のライブラリと連携して面白いビジュアライゼーションができるといいですね!
皆さまもぜひ挑戦して、発表してみてください!
※ TabpyにおけるPythonのコーディングに関してはサポートの範囲外となります。
またサポートもTableauに特化した領域に限定されますのでご留意ください。
※以下関連リンク参照ください。
Tabpy – Tableau + Python 連携 を使ってみよう!(その1:Tabpy導入編)